

- AI Dev - 인공지능 개발자 모임
- 정보공유
- 챗봇 딥러닝
https://ai.googleblog.com/2020/01/reformer-efficient-transformer.html
어제 구글이 Reformer라는 혁신적인 모델을 공개했습니다. 최근 자연어처리 벤치마크의 상위권은 BERT, ALBERT, XLNet 등 트랜스포머를 기반으로 하고 있습니다. 일반적으로 입력의 단어가 많을수록 보다 넓은 문맥을 고려합니다. 하지만 현재는 수천단어 정도가 한계입니다. 반면에 Reformer는 무려 100만 단어를 입력으로 받는다고 합니다.
트랜스포머에서 셀프 어텐션을 위해서는 입력의 각 단어들을 Q, K, V로 변환하여 서로 곱합니다. 예를 들어, 입력이 10개면 10x10=100번의 계산이 필요합니다. 그래서 단어가 증가하면 전체 모델의 크기도 기하급수적으로 커집니다. 동시에 계산시간과 메모리가 늘어나는 문제점이 생기는데, Reformer는 다음과 같이 해결을 했습니다.
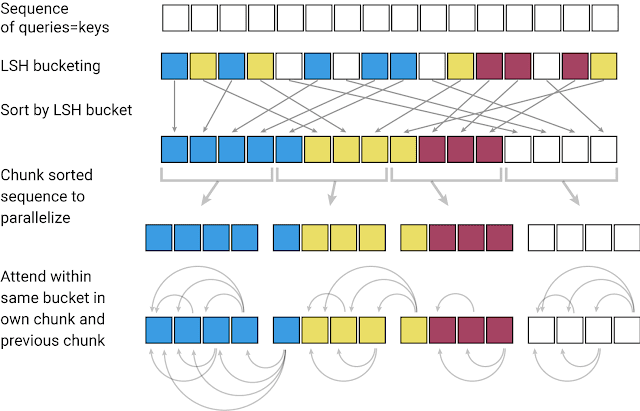
첫째, 어텐션 계산 시간을 LSH(Locality-sensitive-hashing)를 통해 획기적으로 줄였습니다. 비슷한 벡터를 갖는 단어들을 하나의 chunk로 묶습니다. 그리고 chunk 내부와 바로 옆의 chunk하고만 어텐션을 수행합니다.
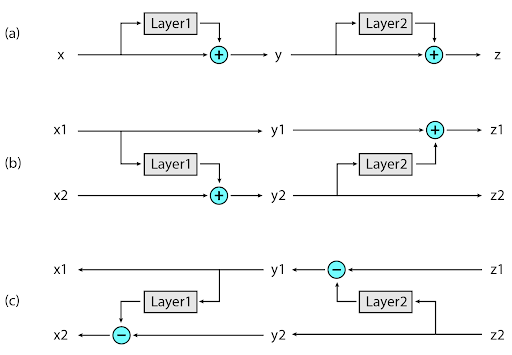
둘째, reversible layers를 사용하여 메모리를 감소하였습니다. 신경망 모델은 역전파를 위해서 각 레이어의 계산 결과를 저장해야 합니다. Reformer는 대신 역전파 시에 필요한 activation값을 그때마다 복원합니다. 그래서 GPU 16GB만으로 충분히 구현이 가능합니다.
언젠가 책 한권을 통째로 읽는 모델이 나올거라고 생각하긴 했습니다. 하지만 이렇게 빨리 개발될 줄은 예상하지 못했습니다. 딥러닝의 발전 속도를 따라잡기가 벅차기만 하네요.