

- AI Dev - 인공지능 개발자 모임
- 정보공유
- 챗봇 딥러닝
Memory Networks(MemNN)는 페이스북에서 발표한 딥러닝 모델로 추론을 통해 질의응답을 할 수 있습니다. 예를 들어, 다음과 같이 문장들과 질문을 함께 입력으로 넣으면 대답을 출력합니다.
< Sentences >
Joe went to the kitchen.
Joe travelled to the office.
Fred went to the kitchen.
Joe left the milk.
Joe went to the bathroom.
< Question >
Where is the milk now? A: office
이런 문제를 해결하기 위해서 RNN과 같은 방법으로 구현할 수도 있습니다. Sentences와 Question 전체를 임베딩하고 한번에 입력하면 정답 단어를 출력합니다. 하지만 문장이 길 경우에는 문장사이의 관계를 학습하기 어렵다는 한계가 있습니다. 그래서 MemNN에서는 별도의 외부 메모리를 사용하여 문장 정보를 저장합니다.
위와 같은 질문에 대해 추론을 하기 위해서 먼저 첫 번째로 연관있는 문장 'Joe left the milk'을 찾아야 합니다. 이를 위해서 스코어 함수라는 것을 사용합니다. 모든 입력 Sentences에 대해서 질문과 연관이 있는 정도를 계산하고 가장 점수가 높은 문장을 선택합니다.
O1(x, m) = argmax(s(x, mi))
s는 스코어 함수, x는 입력 Question, m은 가장 점수가 높은 문장, mi는 모든 Sentences 반복을 의미합니다. 그 다음으로 연관된 문장 'Joe travelled to the office'를 같은 방법으로 찾습니다.
O2(x, m) = argmax(s([x, m1], mi))
스코어 함수에 x와 함께 바로 전에 찾은 연관 문장인 m1도 같이 사용하여 두 번째 연관 문장 m2를 찾습니다.
r = argmax(s([x, m1, m2], w))
그리고 마지막으로 별도의 스코어 함수를 사용하여 가장 점수가 높은 정답 단어 r을 선택합니다. w는 모든 단어 집합을 의미합니다.
결국 메모리란 것은 스코어 함수 s의 파라미터를 학습하는 것을 말합니다. 문제는 특정 메모리 문장 m이 입력 x에 가장 높은 점수를 주도록 스코어 함수를 만드는 방법입니다. 이를 위해서 데이터셋에 supporting facts를 직접 넣어주어야 합니다.
< 학습 데이터 >
1 Joe went to the kitchen.
2 Joe travelled to the office.
3 Fred went to the kitchen.
4 Joe left the milk.
5 Joe went to the bathroom.
6 Where is the milk now? office 4 2
위의 데이터에서 'office'뒤에 있는 숫자가 질문과 연관 있는 문장을 가리킵니다. 그런데 실제로 수집하는 데이터에서는 이런 supporting facts를 사람이 일일이 넣어주는게 불가능합니다. 그래서 페이스북이 End-to-End Memory Networks(MemN2N)를 새롭게 발표하였습니다.
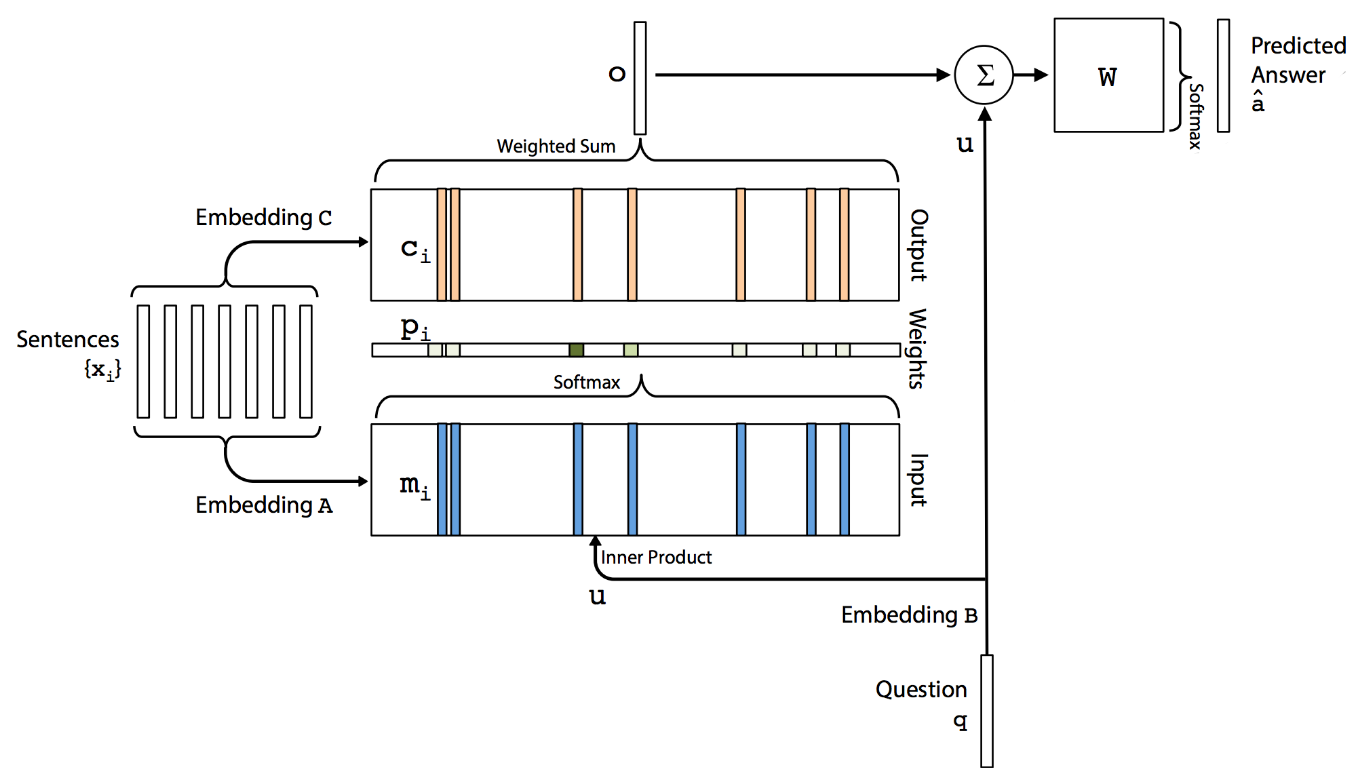
첨부한 사진에서 보는 것처럼 Sentences와 Question이 들어오면 우선 Sentences에 해당하는 메모리만 뽑아 Embedding A를 생성합니다. 그리고 소프트맥스를 통해 입력과 가장 연관이 높은 메모리 문장들이 어떤 건지 확률로 나타내고 다시 이 확률값을 메모리의 Embedding C와 함께 계산합니다. 그리고 마지막으로 입력 Embedding B와 이전 출력 o를 가중치 W로 소프트맥스하여 최종 정답을 선택합니다.
MemN2N의 최종 목표는 학습을 통해 Embedding A, B, C와 W를 찾는 것입니다. 여기서 중간의 소프트맥스가 MemNN에서의 스코어 함수처럼 입력과 연관된 메모리 문장이 무엇인지 알려주는 역할을 합니다. 대신 supporting facts처럼 정답 단어외에 부가적인 정보가 필요없기 때문에 End-to-End라고 부릅니다.
< 참고자료 >
- https://arxiv.org/pdf/1410.3916.pdf
- https://arxiv.org/pdf/1503.08895.pdf
- https://www.slideshare.net/carpedm20/ss-63116251
- https://jhui.github.io/2017/03/15/Memory-network/