

AlphaGo : AlphaGo Pipeline 헤집기
-> https://shuuki4.wordpress.com/2016/03/11/alphago-alphago-pipeline-%ED%97%A4%EC%A7%91%EA%B8%B0/
AlphaGo의 알고리즘과 모델
-> http://sanghyukchun.github.io/97/
DeepMind에서 발표한 논문
-> https://gogameguru.com/i/2016/03/deepmind-mastering-go.pdf
Deep Q-Network로 오목을 학습하는 딥러닝을 구현하려고 공부하고 있습니다. 알파고 알고리즘을 좀 더 자세히 찾아봤는데 알고보니 여기 사용된 강화학습은 DQN가 아니었습니다.
아타리 게임을 학습하던 DQN은 Q-Learning 방법을 사용합니다. 상태 s에서 행동 a를 했을때 Q(s,a)값이 높은 쪽으로 행동을 결정합니다. 좋은 행동이었을 경우 보상값 r을 받고 보상값을 인접 Q테이블에 조금씩 감소시키며 전파합니다. 계속 반복학습을 통해 전체 상태집합에서 어떤 행동이 가장 좋은 것인지 알 수 있습니다.
알파고에서 구현한 강화학습은 이것과 약간 다릅니다. 어떤 알고리즘이 사용되었는지 간단하게 살펴보겠습니다.
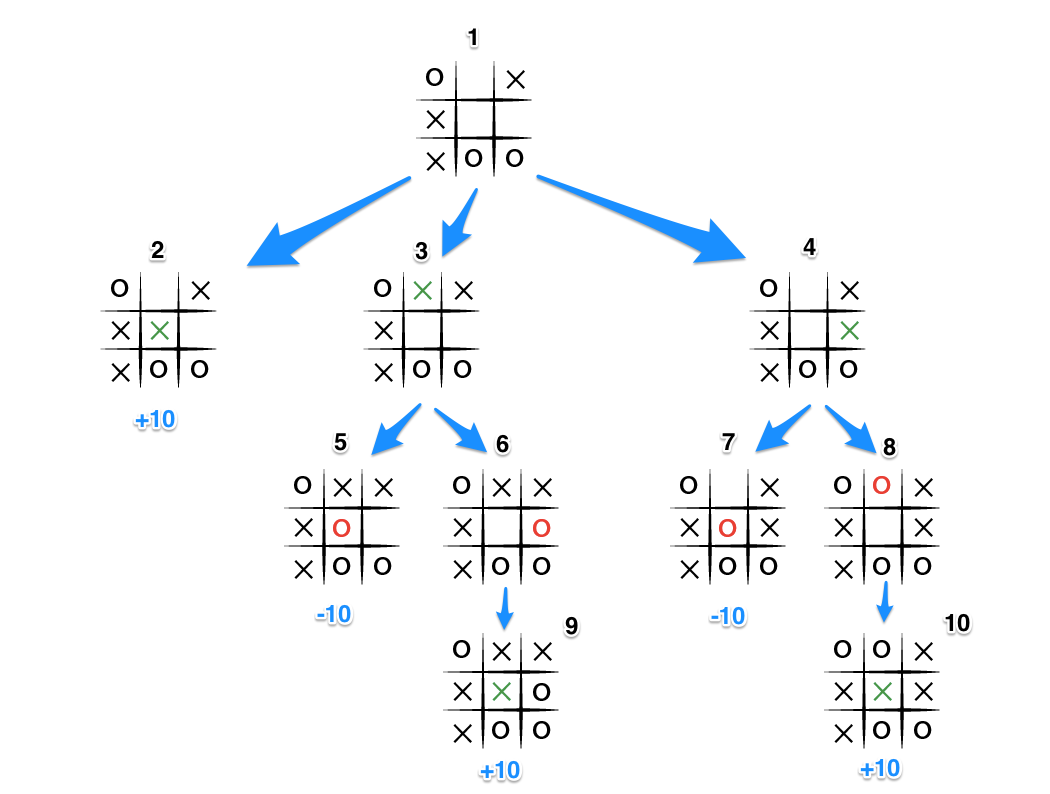
보드게임 인공지능을 위한 대표적인 방법은 미니맥스(Minimax) 알고리즘입니다. 나와 상대방이 번갈아 두는 모든 경우의 수를 구하고 어떤 수가 이길 수 있는 최선인지 검색합니다.
위 그림은 틱택토의 미니맥스 트리인데 이기면 +10, 지면 -10의 평가값을 얻습니다. 트리의 말단 노드까지 검사하여 평가값이 가장 높은 수를 선택합니다.
하지만 바둑은 경우의 수가 천문학적으로 많기 때문에 모든 트리를 검사할 수 없습니다. 그래서 몬테카를로 트리 검색(Monte Carlo Tree Search)라는 방법을 사용합니다. 기본적인 아이디어는 트리의 일부분만 샘플링하여 검색하고 이를 여러번 반복하여 근사치를 얻는 것입니다.
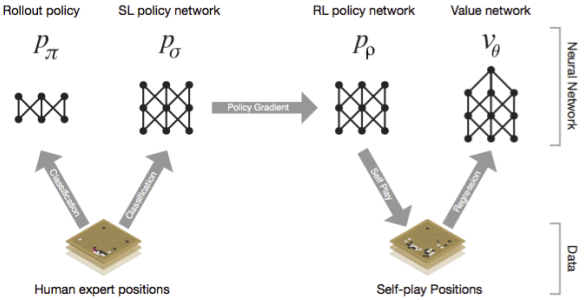
알파고는 MCTS를 기반으로 정책망(Policy Network)와 가치망(Value Network)를 사용합니다. 트리를 샘플링하여 가치를 칠때 최대한 연관이 높은 것을 선택해야 합니다. 바둑에서 다음 수는 보통 이전 수 근처에 있지 멀리 떨어진 곳에 두지 않습니다.
이렇게 좋은 쪽으로 트리를 선택하기 위해서 정책망으로 판단을 하는데 이걸 딥러닝 CNN으로 구현했습니다. 프로기사가 둔 3000만개의 기보를 사용하여 지도학습을 했다고 합니다. 학습된 정책망으로 현재 상태에서 최적의 수를 찾아내고 그쪽 방향으로 계속 검색합니다.
하지만 이런 방법으로는 기보에 없는 새로운 수를 찾을 수 없는 한계가 있습니다. 이를 극복하기 위해 지도학습 정책망과 함께 강화학습 정책망을 이용합니다. 강화학습 정책망은 지도학습 정책망의 가중치를 초기값으로 하여 생성합니다.
그리고 지도학습 정책망끼리 대결을 하여 그 결과에 따라 강화학습 정책망의 가중치를 조정합니다. Q러닝과는 다른 방법으로 직접 가중치를 조정하는데 논문에는 자세한 방법이 나와있지 않습니다.
정책망으로 트리를 선택한 다음에는 가치망으로 좋은 수인지를 평가해야 합니다. 가치망에서도 강화학습을 사용하는데 이것 역시 Q러닝은 아닙니다.
정책망끼리 대결을 하여 승패를 기록하고 이 데이터로 CNN 지도학습을 합니다. (바둑판 상태, 평가값)의 데이터인데 많이 이긴 바둑판의 상태일 경우 높은 평가값을 가집니다.
지도학습 정책망 CNN이 최선의 수를 찾는 분류작업이라면 가치망 CNN은 현재 바둑판의 상태에서 평가값을 예측하는 것이라 할 수 있습니다.
정리하면 알파고에서 사용된 딥러닝은 모두 세가지 입니다.
1. 지도학습 정책망
2. 강화학습 정책망
3. 강화학습 가치망
< 인공지능 개발자 모임 >
- 페이스북 그룹에 가입하시면 인공지능에 대한 최신 정보를 쉽게 받으실 수 있습니다.
- https://www.facebook.com/groups/AIDevKr/