

한달 전 구글이 또 혁신적인 모델을 공개했습니다. MLP-Mixer가 그 주인공입니다. 이름 그대로 기본 신경망인 MLP(Multi Layer Perceptrons)만 사용한 이미지 인식 모델입니다. 하지만 CNN이나 Tranformer 기반의 모델과 거의 동급의 성능을 보이고 있습니다. 대신 속도는 훨씬 빨라졌습니다.
ViT(Vision Transformer)는 Self-Attention을 수행할 때 모든 이미지 패치들을 서로 곱하여 계산합니다. 예를 들어, 한 사진에 ABC라는 패치들이 있다면 AA, AB, AC, BA, BB, BC, CA, CB, CC 총 3^2번 계산을 합니다. 이렇게 각 패치들을 서로 비교하면서 어디에 집중할지, 어느 패치가 이 사진에서 중요한 의미인지를 파악합니다. 문제는 패치가 많아질수록 n^2번 계산을 하기 때문에 속도가 느려집니다. 반면에 MLP-Mixer는 패치의 수가 증가해도 선형적으로만 계산량이 높아집니다. 덕분에 ViT와 비슷한 성능에도 훨씬 빠른 속도를 자랑합니다.
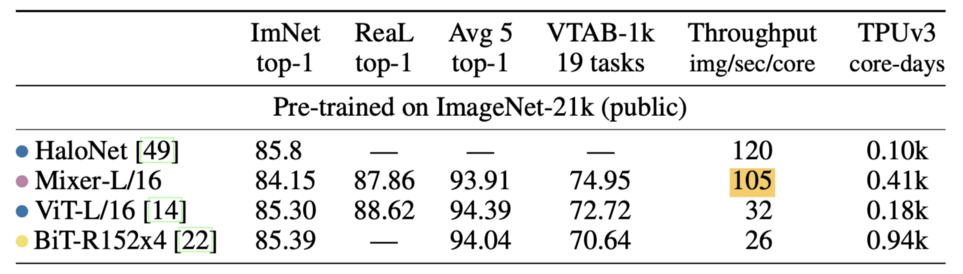
아래 사진을 보면 MLP-Mixer의 동작방식을 한 눈에 이해하실 수 있습니다. 당연히 그냥 평범한 신경망은 아닙니다. 핵심적인 아이디어는 각 이미지 패치를 서로 섞는다는(mix) 것입니다. 사진 상단 왼쪽을 보면 색깔별로 이미지 패치 입력이 들어옵니다. 이를 전치행렬(T)로 행과 열을 바꿉니다. 그리고 MLP에 넣어서 계산을 하면 각 이미지 패치들이 섞이게 됩니다.
사실 이건 Transformer에서 Self-Attention과 비슷합니다. Self-Attention도 결국 모든 패치들을 서로 곱해 섞는 것이니까요. CNN도 마찬가지입니다. 각 필터들을 거친 피처맵들을 섞어 하나의 입력으로 만들고 다음 레이어에 전달합니다. 단지 ViT, CNN, MLP-Mixer는 섞는 방법만 다를 뿐입니다.
2017년 처음 구글이 Transformer를 발표했습니다. 그 이후 BERT, GPT와 같은 자연어처리에서부터 ViT 같은 이미지 인식까지 높은 성능을 보여왔습니다. 그랬던게 또 새로운 변화가 찾아왔습니다. 앞으로 MLP-Mixer와 같은 방식으로 구현된 다양한 모델들이 개발되지 않을까요. 아무튼 딥러닝의 발전속도가 정말 빠르네요. 그래도 그 구조가 단순해지고 있다는 점은 환영할 만합니다.
< 참고자료 >
- https://visionhong.tistory.com/27?category=947242
- https://towardsdatascience.com/google-releases-mlp-mixer...