

https://arxiv.org/pdf/1906.02940.pdf
며칠 전 구글에서 또 놀랄 만한 논문을 발표했습니다. Selfie(Self-supervised Pretraining for Image Embedding)이란 비지도학습 이미지 사전훈련 모델입니다.
지금까지 이미지 사전훈련은 지도학습으로 먼저 학습을 한 후, 모델의 일부분을 추출하여 재사용을 하는 방식이었습니다. 이렇게 전이학습을 하면 새로운 도메인에 대한 데이터가 적어도, 더 빠르고 정확하게 학습이 된다는 장점이 있습니다.
이런 사전훈련을 자연어처리에 적용한 것이 BERT입니다. 중요한 차이점은 지도학습이 아니라 비지도학습의 한 방법인 자기지도학습(self-supervised)를 사용했다는 것입니다. 사람이 별도로 작성한 라벨이 필요없이 입력 데이터에서 자체적으로 라벨을 만듭니다. 다음과 같이 문장에서 일부 단어를 마스킹하고, 그 단어를 예측하는 모델입니다.
< 원문 >
딥러닝은 인공지능의 한 종류입니다.
< 예측 >
딥러닝은 [MASK]의 한 종류입니다.
-> 인공지능
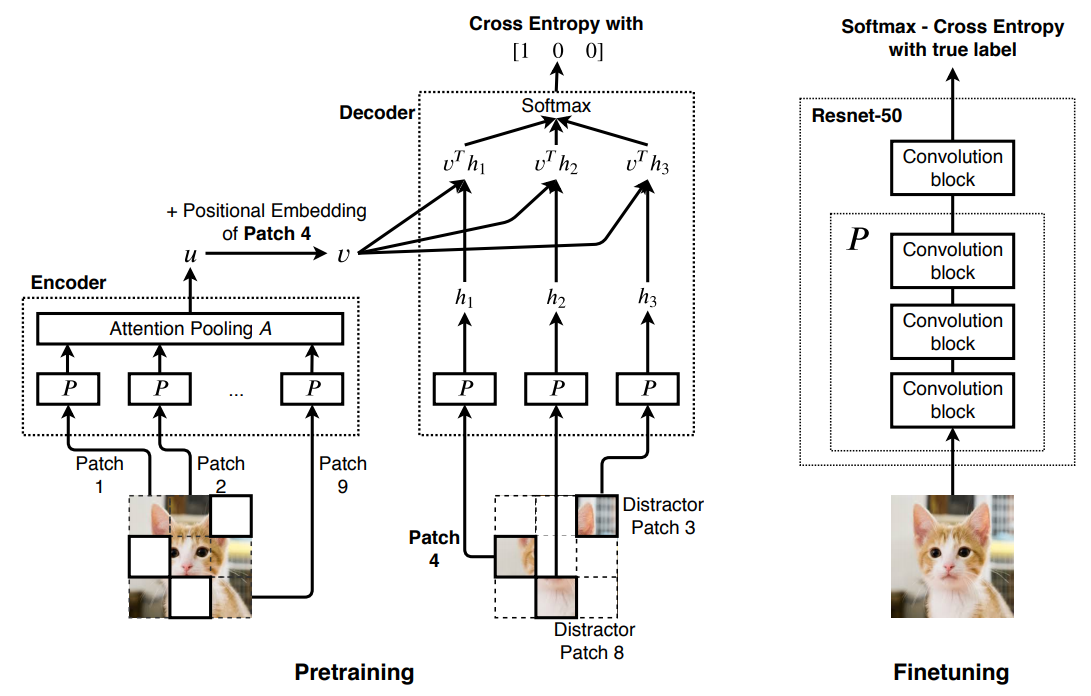
Selfie는 바로 BERT의 마스킹 자기지도학습을 이미지에 적용한 모델입니다. 스크린샷처럼 먼저 사진을 격자로 나눕니다. 그리고 일부 격자를 제외하고 각 격자를 CNN 모델인 P로 특징을 추출합니다. 이 특징 벡터들을 다시 트랜스포머 모델인 A로 어텐션 풀링을 하여 최종 벡터 u를 생성합니다. 여기에 예측하고자 하는 4번째 격자(Patch4)의 위치 정보를 추가하여 벡터 v를 만듭니다. 여기까지가 인코더 부분입니다.
디코더에서는 4번째 위치의 격자가 실제 어떤 격자인지 분류하는 역할을 합니다. 인코더에서 사용하지 않은 격자들(Patch4, Patch8, Patch3)을 입력으로 넣고 P로 특징을 추출합니다. 이를 다시 인코더의 최종 출력인 v와 곱합니다. 그다음 softmax로 3개의 격자 중 어느 것이 4번째 격자인지 판단합니다.
이렇게 사전훈련이 끝나면 CNN인 인코더의 P만 떼어내서 레이어를 추가하고 새로운 모델을 만듭니다. 그리고 자신의 데이터로 새로 학습을 수행합니다.
페이페이 리는 ImageNet에 있는 수천만장의 사진들에 라벨을 달았습니다. 아마존 미케니컬 터크로 전 세계에 있는 수만명의 사람들을 고용했기에 가능한 일이었습니다. 앞으로 새로운 사진들이 계속 생겨날 테니 동일한 라벨 작업을 계속 반복해야 합니다. 하지만 만약 비지도학습으로 사전훈련을 할 수 있다면 이런 과정이 필요 없습니다. 내 프로젝트에 필요한 소수의 데이터만 라벨을 작성하고 사전훈련 모델로 전이학습을 합니다. 이렇게 하면 훨씬 적은 노력과 비용으로 학습할 수 있습니다.
제프리 힌튼과 얀 르쿤은 앞으로 비지도학습이 딥러닝의 새로운 돌파구가 될 것이라 말했습니다. Selfie 사전훈련 모델이 그 시작이 될지도 모르겠습니다.