

페이스북 AI 연구소의 수장인 얀 르쿤이 최근 발표한 자료입니다. 앞부분에서는 딥러닝에 대해 간략히 소개합니다. 중요한 것은 뒷부분인데, 비지도학습의 한 방법인 자기지도학습(Self-Supervised Learning)을 자세히 다루고 있습니다.
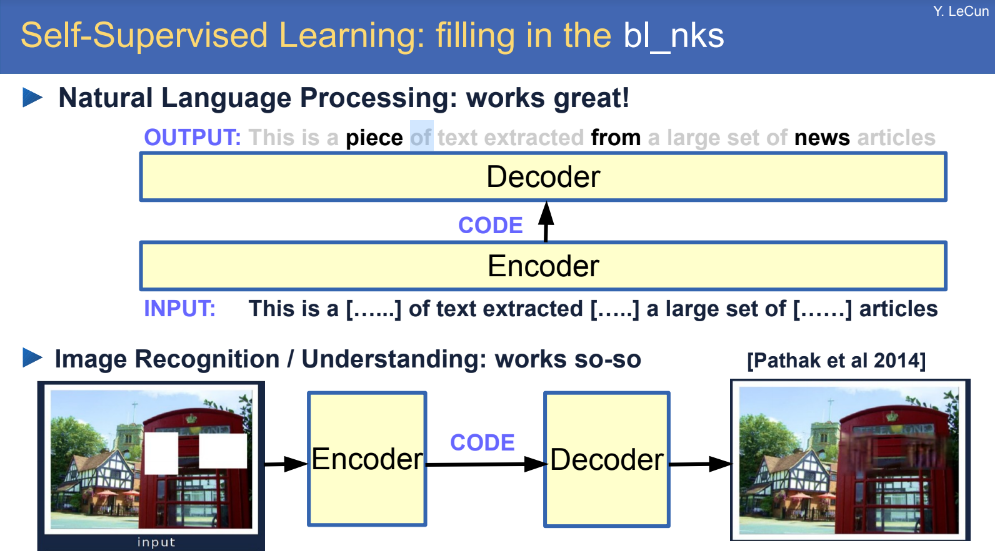
작년 말부터 BERT와 GPT2 등 자연어처리에서 자기지도학습이 놀라운 성능을 보여왔습니다. 앞으로 이미지나 영상에서도 이 방법이 주류로 떠오르지 않을까 합니다. 사람은 보통 시각정보를 통해 학습을 합니다. 눈으로 입력받은 연속적인 화면을 보고 다음 화면을 예측합니다. 이를 통해 자연스럽게 세상의 상식을 배웁니다. 예를 들어, 공을 떨어뜨리면 현재 위치보다 아래로 향할 것이라고 추측합니다.
마찬가지로 시계열의 영상을 사용하여 자기지도학습이 가능합니다. 과거의 이미지들이 입력으로 들어가고 다음 이미지를 예측합니다. BERT와 GPT2가 텍스트를 사용한다면, 여기서는 화면이라는 차이가 있을 뿐 기본적인 원리는 비슷합니다. 이렇게 사전훈련을 하여 세상에 대한 지식을 구축합니다. 그리고 이 모델을 전이학습을 하여 다양한 곳에 응용할 수 있습니다.
작년 초에 발표된 월드 모델(World Models)이 이런 방식과 유사합니다. VAE로 화면의 특징 벡터를 뽑아내고, 이를 RNN을 통해 다음 화면을 예측합니다. 그리고 미래의 상황에서 어떤 행동을 할지 배우는 강화학습을 수행합니다.
http://aidev.co.kr/deeplearning/4304
문제는 영상을 학습하기 위해서는 그만큼 자원과 시간이 많이 든다는 점입니다. 또한 사전훈련 모델을 효과적으로 전이학습하는 방법을 아직 확실하게 모릅니다. 하지만 올해나 내년에는 이렇게 영상을 자기지도하는 모델이 크게 떠오르지 않을까 생각됩니다.