

딥러닝의 여러 분야 중에서도 가장 눈에 띄면서 화려한 것은 역시 GAN입니다. 보통 GAN은 임의의 잠재벡터(latent vector) z를 입력으로 넣으면 이미지를 출력합니다. 이미지를 표현하는 전체 잠재공간(latent space)을 확률적으로 재구성할 수 있기 때문입니다. 이는 딥러닝의 장점인 일반화 덕분입니다. 예를 들어, 100개의 학습 이미지만 가지고도 10000개의 잠재공간 이미지를 만드는게 가능합니다. 그래서 z를 변형하면 나머지 9900개의 새로운 사진이 생성됩니다.
자연어처리에서 쓰는 word2vec과 개념이 유사합니다. word2vec이 단어를 벡터로 표현한다면, GAN은 이미지를 벡터로 표현합니다. '왕-남자+여자=여왕' 같은 벡터 연산이 GAN에서도 가능합니다. 얼굴 z에 안경 벡터를 추가하여 모델에 넣으면 안경을 쓴 얼굴이 나옵니다.
문제는 이런 특징 벡터를 어떻게 구하는가 입니다. 무식하게는 임의로 z를 하나씩 변형해보면서 찾을 수 있습니다. 또는 안경 안쓴 사진의 z와 안경 쓴 사진의 z의 차이를 계산하여 특징 벡터를 추출합니다. 어째든 이런 작업이 노동집약적이고 상당히 불편합니다. 최근 이를 보완해줄 새로운 모델이 공개됐습니다.
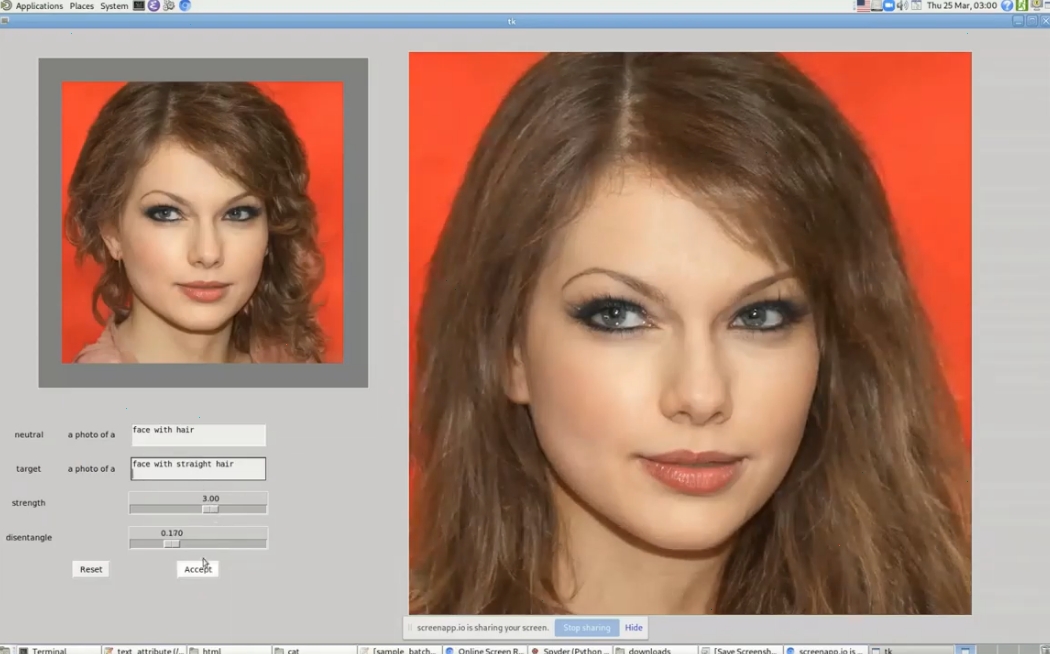
StyleCLIP은 StyleGAN과 CLIP을 결합했습니다. StyleGAN에서 이미지를 변형할 때, 벡터가 아니라 CLIP처럼 말로 설명하여 직관적으로 할 수 있습니다. 고양이 사진과 함께 '귀여운 고양이'라는 텍스트를 넣으면 고양이가 귀여운 모습으로 바뀌어서 생성됩니다.

CLIP(http://aidev.co.kr/deeplearning/10254)은 사진 인코더와 텍스트 인코더로 구성된 분류 모델입니다. 강아지 사진을 사진 인코더에 넣고 사진 벡터를 구합니다. 그다음 '강아지 사진'이라는 텍스트를 텍스트 인코더에 넣고 텍스트 벡터를 구합니다. 이 두 벡터가 유사하다면 그 사진을 강아지라고 판단합니다.
그렇다면 어떻게 CLIP을 StyleGAN에 적용할 수 있을까요. 만약 놀라는 사진으로 변형하고 싶다면 '놀람' 텍스트를 CLIP 텍스트 인코더로 벡터를 구합니다. 마찬가지로 놀라는 이미지를 StyleGAN으로 만들고 이를 CLIP 사진 인코더에 넣어 벡터를 구합니다. 이 두 벡터의 코사인 유사도로 손실함수를 정의합니다. 그러면 StyleGAN의 이미지와 텍스트가 서로 매칭되도록 학습됩니다.
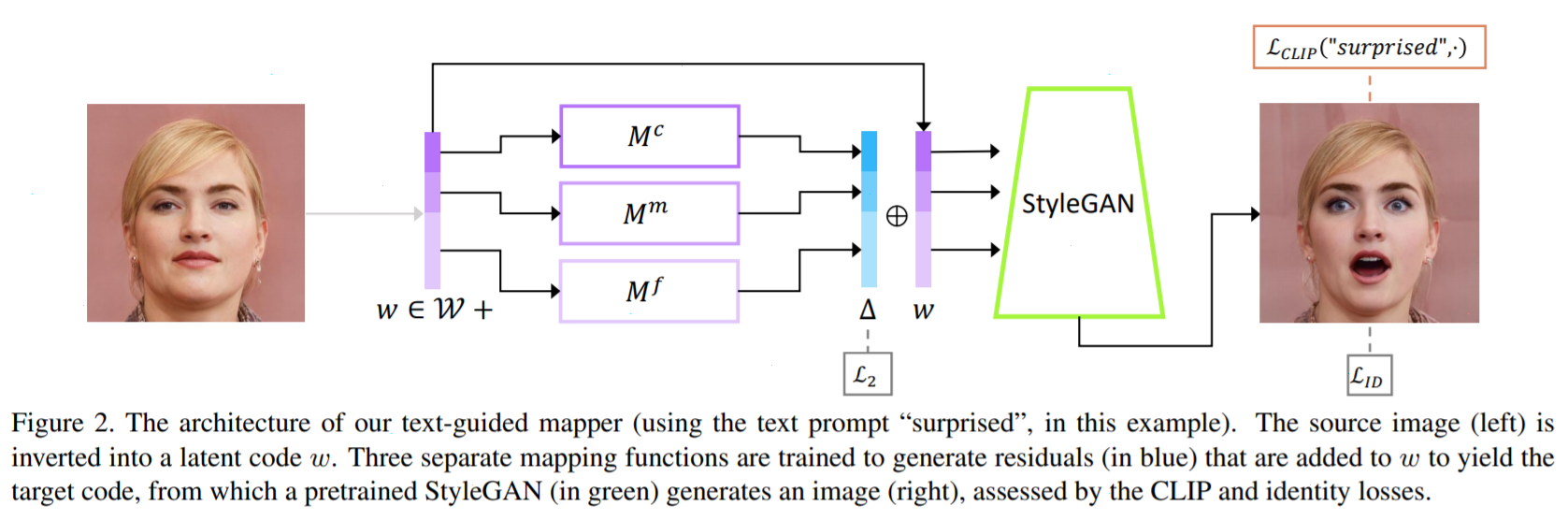

OpenAI에서 CLIP을 발표한게 올해 1월이었습니다. 불과 3개월만에 이를 응용하여 새로운 논문을 냈다는게 대단합니다. 그만큼 딥러닝의 발전속도가 빠르다는 뜻입니다. 동시에 경쟁 역시 치열하다고 볼 수 있습니다. 앞으로 CLIP에 기반한 모델들이 지속적으로 나오지 않을까 합니다.
< 유튜브 영상 >
https://www.youtube.com/watch?v=5icI0NgALnQ
< GitHub >
https://github.com/orpatashnik/StyleCLIP