

- AI Dev - 인공지능 개발자 모임
- 정보공유
- 게임 인공지능

소스코드 및 실행 : 첨부파일
게임트리(Game Tree)의 정의
체스나 장기 등 두 플레이어가 번갈아서 수를 쓰는 게임들은 주로 게임트리라는 개념을 사용한다. 게임트리는 각각의 노드가 게임의 한 상태(말들의 위치)를 의미하며, 각 노드의 자식 노드들은 한 수 이후에 도달할 수 있는 다음 위치들을 의미하는 특별한 트리이다. 그러한 게임의 컴퓨터 플레이어는 게임트리를 이용해서 다음 수순을 미리 예측하고 가장 유리한 수를 찾는다.
복잡한 게임의 경우에는 가능한 수순의 경우의 수가 매우 크기 때문에 게임트리를 적절한(컴퓨터의 속도와 용량을 고려해서) 크기로 제한하기 위해서는 일정 수준 이후의 수들의 가치를 추측할 수 있어야 하며, 그러자면 적절하고 유효한 평가 함수가 필요하다
제로섬 게임(Zero-sum Game)에서의 게임트리 사용
게임트리 검색에 깔린 가정은, 한 플레이어에게 유리한 수는 상대 플레이어에게 불리한 수라는 것이다. 즉 나는 보드의 평가를 내 쪽으로 최대화하는 방향으로, 그리고 상대쪽으로 최소화하는 방향으로 플레이를 하는 것이다. 이와 같은 '나의 이득은 상대의 손실' 형태의 게임을 제로섬 게임이라고 부른다.
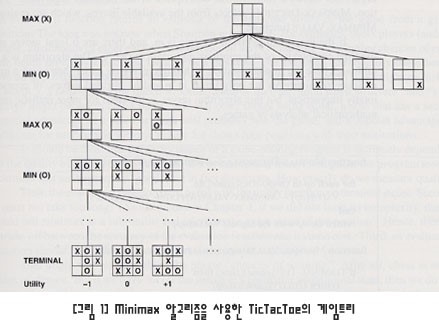
예를 들면 3목(Tic-Tac-Toe) 게임이 제로섬 게임인데 [그림1]에 제로섬 게임트리의 일부분이 나와 있다.
미니맥스 알고리즘(Minimax Algorithm)
위의 게임트리에서, 한 수준 깊이 검색을 한다면 한 플레이어는 최상의 결과(보드 평가함수에 의해 정의된)를 낼 수 있는 보드 위치로 말을 움직이면 된다. 두 수준 깊이 검색에서, 플레이어1은 플레이어2가 위에서 말한 방식대로 한 수준 깊이 검색을 수행할 것이라고 가정할 수 있다. 따라서 플레이어 1은 다음 턴에서 플레이어2가 최고의 결과를 얻지 못하게 하는 수(이는 또한 플레이어1에게 최고의 수가 된다)를 두게 된다. 이런 방식으로 시간과 용량이 허용하는 한도 내에서 계속 깊이 들어간다. 이러한 방법으로 상대에 대한 최소값을 찾음으로써 플레이어 자신에 대한 최대값을 얻는 게임트리 검색방법을 미니맥스 알고리즘이라 한다.
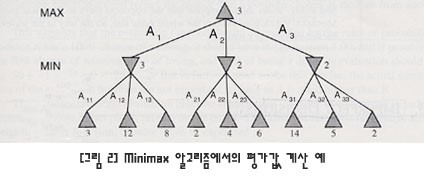
[그림2]는 미니맥스 알고리즘을 사용한 예이다. 위로 향하는 삼각형 노드는 자신의 수이고, 아래로 향하는 삼각형 노드는 상대의 수이다. 그리고 각각의 숫자는 자신을 기준으로 했을 때의 평가값 수치이다. 그림처럼 두 단계 깊이까지만 탐색을 수행한다면, 먼저 제일 밑의 노드들에서 각각 평가값들을 계산한다. 그 위 노드에서 상대방은 밑의 노드들중에서 평가값이 가장 작은수를 선택하게 된다(자신을 기준으로 계산한 평가값이기 때문에 상대방에게는 가장 작은 평가값이 가장 좋은 수가 되기 때문이다). 그리고 다시 제일 위의 노드에서는 밑의 세 개의 노드중에서 평가값이 가장 큰 수를 선택하게 되는데, 그래야만 상대가 선택하는 수가 가장 좋지 않은 수가 되고 그것이 또한 자신에게 가장 좋은 수가 되기 때문이다.
탐색의 수를 줄이기 위한 알파베타 가지치기(Alpha-Beta Pruning)
Newell, Simon, Shaw는 1958년 알파베타 가지치기라는 개념을 만들어 냈다. 이 개념은 어떠한 경우 게임트리의 특정한 가지는 더 이상 탐색해 나갈 필요가 없다는 점에 기반한 것이다.
[그림3]에서 왼쪽 노드들을 탐색하고 나면 현재까지 MIN의 최소값이 3이라는 것을 알 수 있다. 그리고 가운데 노드들을 탐색했을 때 첫 노드의 평가치가 2라면, 이는 현재까지의 최소값인 3보다 작기 때문에 상대방은 항상 이 노드를 선택하게 될 것이다. 그러므로 자신은 절대 이 노드쪽으로 수를 두면 안되기 때문에 가운데 노드쪽으로는 선택하지 않게 될 것이다. 그러므로 더 이상 가운데 노드의 자식들을 탐색을 수행할 필요가 없다.
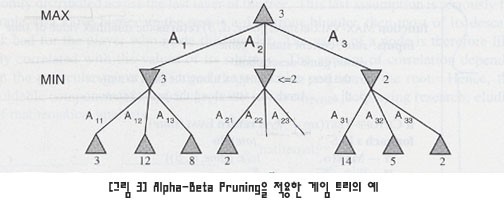
이를 좀더 일반화시킨다면, '상대가 현재 위치 이후의 어떤 지점에서 더 유리한 결과를 얻을 수 있다면, 현재 위치를 만드는 수는 나에게 무조건 불리하므로 더 이상 고려할 필요가 없다'는 뜻이 된다. 즉 나에게 불리한 수가 만들어지는 지점부터는 트리의 '가지를 쳐도(pruning)' 되는 것이다.
어떤 노드에서 가지를 쳐도 될 것인가를 구체적으로 판단하려면, 게임트리 검색의 매 순간마다 현재까지의 탐색에서 나에게 가장 유리한 수의 최대값과 상대에게 가장 유리한 최대값을 기억하고 있어야 한다. 현재의 검색에서 상대의 현재 최대값이 나의 현재 최대값보다 크다면 그 부분 이하는 더 이상 고려할 필요가 없다. 이 때 나의 현재 최대값을 알파, 상대의 현재 최대값을 베타라고 부른다.
[참고자료]
- Game Programming Gems 1권, p.333 ~ p.339
- Artificial Intelligence A Modern Approach, Stuart Russell, p.122 ~ p.141
< 인공지능 개발자 모임 >
- 페이스북 그룹에 가입하시면 인공지능에 대한 최신 정보를 쉽게 받으실 수 있습니다.
- https://www.facebook.com/groups/AIDevKr/