

- AI Dev - 인공지능 개발자 모임
- 정보공유
- 자연어처리
글 수 72
https://brunch.co.kr/@kakao-it/189
머신러닝에서 자연어를 처리하려면 우선 컴퓨터가 이해할 수 있는 형식으로 변환해야 합니다. 가장 쉬운 방법은 One-Hot Encoding을 사용하는 것입니다.
전체 단어의 수 만큼 벡터의 차원을 만들고 각 단어마다 하나의 차원에 대입합니다. 하지만 이 방식은 벡터의 차원이 너무 커지기 때문에 학습이 힘들다는 단점이 있습니다.

두번째 방법은 Word Embedding으로 0, 1과 같이 두개의 값이 아니라 0~1 사이의 벡터값을 가집니다. 하나의 단어마다 각 벡터의 차원을 모두 사용하기 때문에 벡터의 크기를 작게 할 수 있습니다. 또한 비슷한 단어는 벡터의 값 역시 유사하기 때문에 학습이 더 잘된다는 장점이 있습니다.
예를 들어, 위와 같은 단어는 다음과 같이 표현할 수 있습니다.
과학 -> (0.5, 0.1, 0.3)
공학 -> (0.4, 0.2, 0.5)
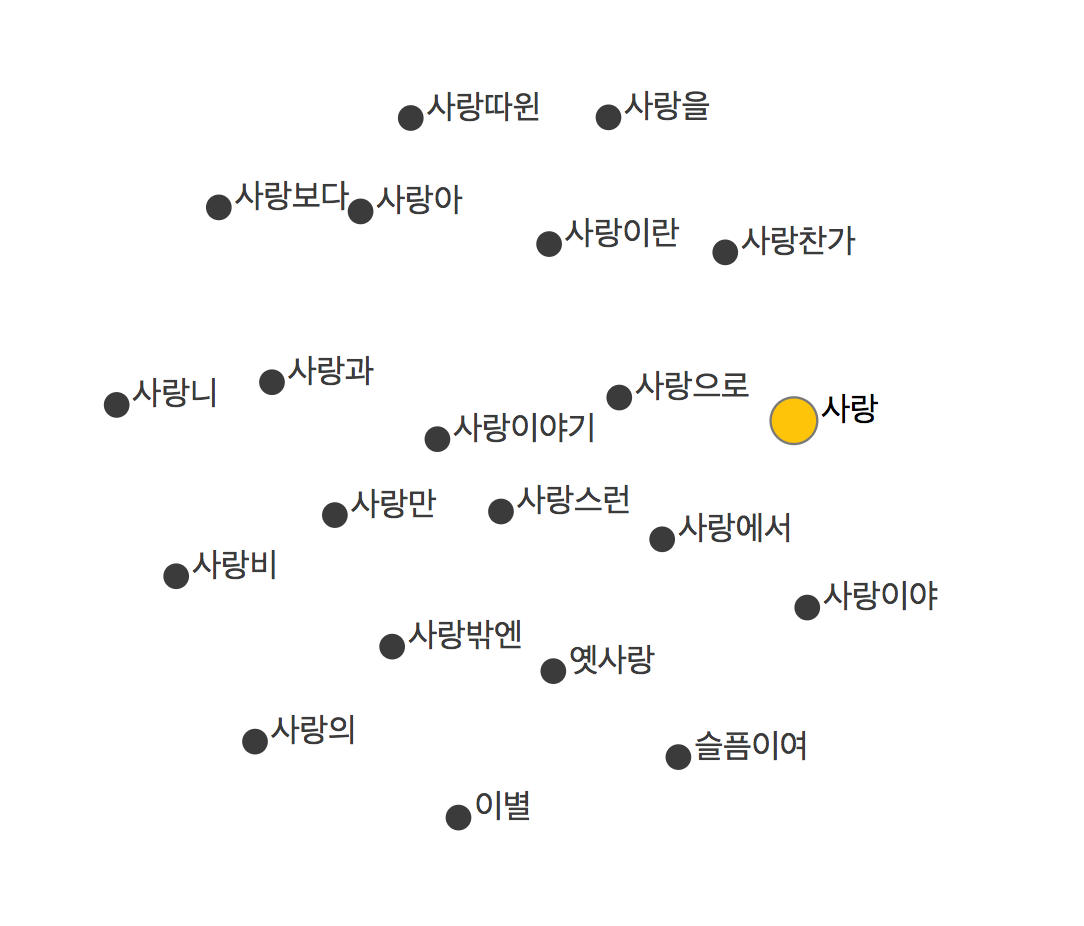
위의 글에서 카카오브레인이 만든 WordWeb이라는 것을 소개하고 있습니다. 워드 임베딩을 사용해서 입력으로 받은 단어와 비슷한 뜻을 가진 단어를 보여주는 기능입니다.
아래 링크에서 직접 테스트 할 수 있습니다.
-> http://ling.kakaobrain.com/wordweb