

- AI Dev - 인공지능 개발자 모임
- 정보공유
- 강화학습
http://keunwoochoi.blogspot.kr/2016/06/andrej-karpathy.html
딥 강화학습의 대표적인 방법은 Deep Q-Network입니다.
바로 이 기술로 딥마인드가 아타리 게임을 학습시켰습니다.
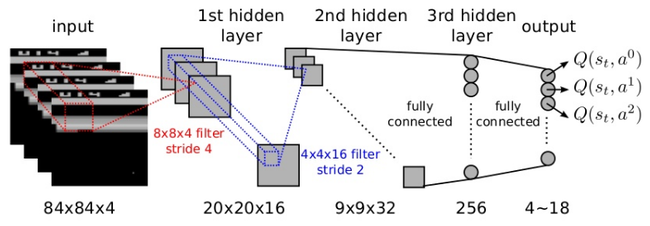
DQN는 기존 Q-Learning에서 Q테이블을 딥러닝 CNN으로 변경한 것입니다. 아타리 게임의 픽셀정보를 입력으로 하여 신경망을 통해 현재 픽셀 상태 s에서 행동 a를 결정합니다. 그리고 보상값을 받아 주변 상태집합으로 이 보상값을 전파하도록 Q값을 학습시킵니다.
이를 반복하면 전체 상태로 보상값이 퍼져나가 학습이 됩니다. 그러면 현재 상태일때 어떤 행동을 해야 미래의 상태에서 좋은 결과를 얻을 수 있는지 알 수 있게 됩니다.
그런데 DQN와 다른 강화학습 알고리즘으로 정책 그라디언트(Policy Gradients)가 있습니다.
알파고에서는 이 방식으로 스스로 대결하면서 학습을 수행하였습니다.
정책 그라디언트는 Q함수로 보상값을 조금씩 전체 상태집합에 전파하지 않습니다.
그보다는 승패가 결정될때까지 (입력, 목표값)이라는 데이터를 수집하고
수집한 데이터를 사용해 게임의 결과를 반영하여 신경망의 가중치를 변경합니다.
예를 들어 200 프레임에 게임이 끝나고 승부에서 졌다고 가정해봅시다.
(1프레임 픽셀집합, UP) -> 가중치 내림
(2프레임 픽셀집합, DOWN) -> 가중치 내림
...
(200프레임 픽셀집합, DOWN) -> 가중치 내림
이렇게 200프레임 동안 했던 행동들이 좋지 않아 졌다고 생각하기 때문에 가중치를 모두 내립니다.
저도 아직 코드를 실행해 보진 않았는데 시간날때 한번 돌려봐야겠네요.
< 인공지능 개발자 모임 >
- 페이스북 그룹에 가입하시면 인공지능에 대한 최신 정보를 쉽게 받으실 수 있습니다.
- https://www.facebook.com/groups/AIDevKr/