https://n.news.naver.com/mnews/article/308/0000028280?sid=102
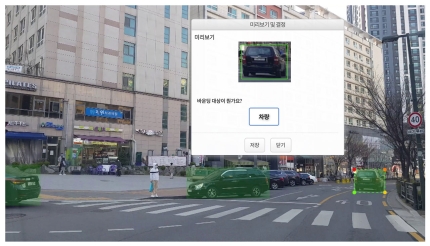
"바운딩 입문은 ‘동물’ 바운딩이다. 바운딩 하나당 20포인트(20원)를 지급한다. 한 사진 안에 동물이 4마리 있으면 각각 바운딩을 한다. 그러면 80원이다. 클릭, 드래그, 더블클릭만 하면 되는 일이라 간단할 줄 알았는데, 예상보다 쉽지 않았다. 동물을 바운딩할 때 이미지 상하좌우에 여백이 남지 않도록 세밀하게 작업해야 한다. 그러지 않으면 검수 과정에서 ‘반려’가 떠 재작업을 해야 한다."
"이미지 바운딩 다음은 ‘텍스트 태깅’ 실습이다. 서비스 약관이나 법조문 옆에 질문 문항이 있다. 답에 해당하는 문구를 마우스로 긁으면(태깅) 된다. 질문 난이도에 따라 건당 20원, 40원씩이다. 이런 데이터는 검색엔진 소프트웨어 개발에 사용된다. 퀴즈처럼 쉽게 풀 줄 알았는데, 약관·법조문의 문장을 꼼꼼히 읽어야 했다. 대충 읽어서는 ‘태깅’하기가 어려웠다."
지금 딥러닝은 대부분 지도학습으로 이루어져 있습니다. 이를 위해서는 반드시 사람이 작성한 정답 라벨이 있어야 합니다. 현재 딥러닝을 탄생시킨 이미지넷 데이터도 마찬가지입니다. 전세계 수많은 사람들이 크라우드소싱으로 사진의 라벨을 달았다고 합니다.
요즘은 점점 지도학습을 벗어나려는 추세입니다. 이미 자연어처리에서는 사전훈련 모델을 만드는데 자기지도학습을 주로 사용합니다. 앞의 문장과 이어지는 다음 단어를 예측하는 경우 라벨을 자동으로 생성할 수 있습니다. 이밖에도 다양한 자기지도 방법이 계속 개발되고 있습니다.
하지만 아직은 사람의 노력이 반드시 필요합니다. 만약 기계가 우리의 도움없이 스스로 학습하게 되는 날이 온다면 어떻게 될까요. 그때는 레이 커즈와일이 말한 특이점이 멀지 않을 듯 합니다.
]]>