

- AI Dev - 인공지능 개발자 모임
- 정보공유
- 챗봇 딥러닝
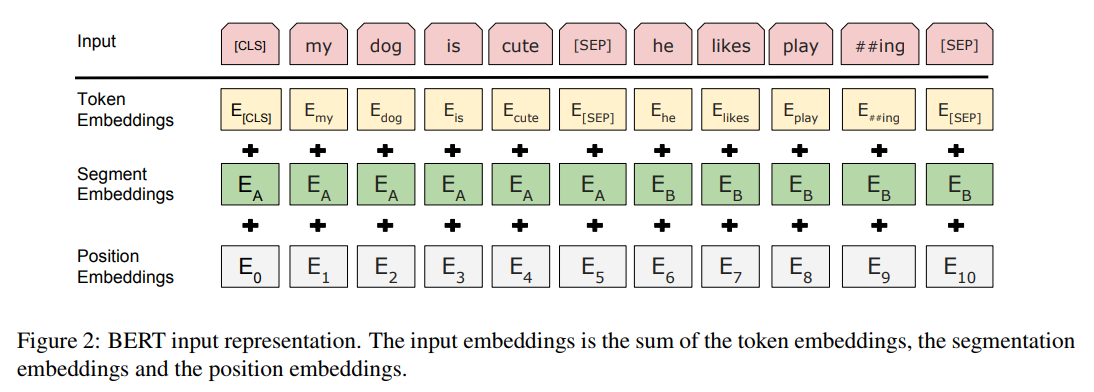
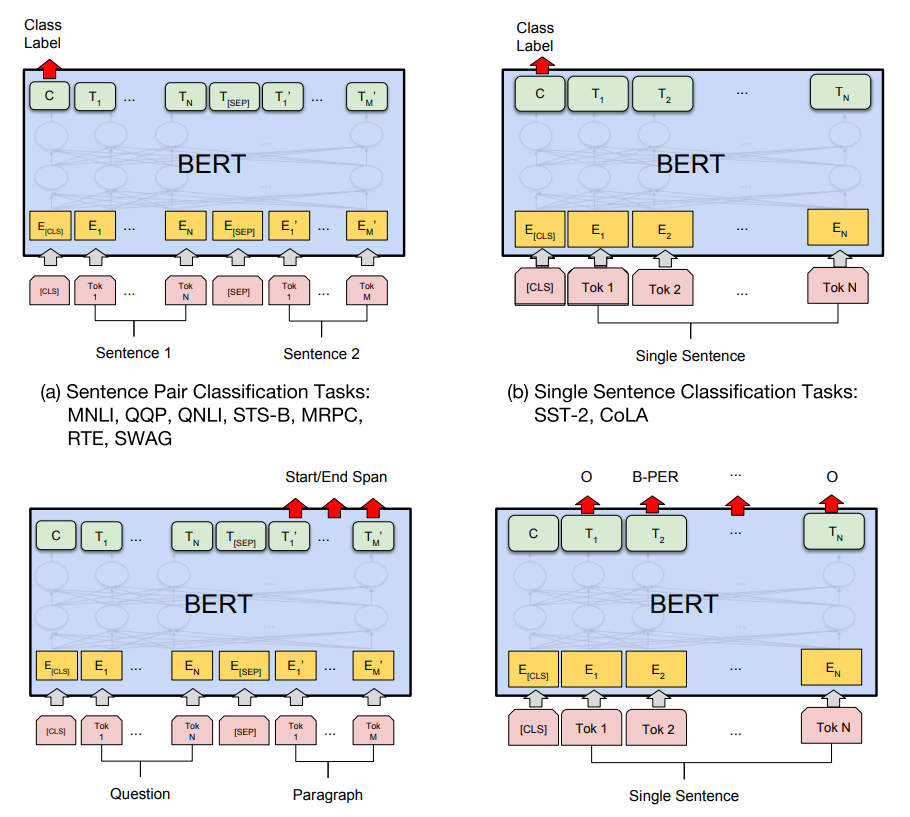
최근 발표된 구글의 딥러닝 언어 모델(language model)인 BERT가 큰 화제가 되고 있습니다. 특히 자연어처리 데이터셋 벤치마크인 GLUE(General Language Understanding Evaluation)와 SQuAD(Stanford Question Answering Dataset)에서 인간보다 더 뛰어난 성적을 보여주어 많은 이들을 놀라게 했습니다.
BERT는 구글의 셀프 어텐션 신경망 모델인 Transformer로 되어있습니다. 그리고 미리 사전훈련(pre-training)을 한 후 여러가지 자연어 문제에 파인튜닝(fine-tuning)만 하여 공통적으로 적용이 가능합니다.
예전에는 특정 모델을 만들때 해당 문제의 데이터만 가지고 처음부터 끝까지 학습시켰습니다. 만약 Seq2Seq로 챗봇을 구현한다면 '질문/대답'의 데이터들을 모으고 이것으로 모델을 학습합니다.
반면에 사전훈련은 아무런 레이블이 없는 코퍼스를 특정한 방법으로 비지도학습을 합니다. 그렇게 언어의 패턴이 담긴 모델을 만든 다음 그걸 전이학습이나 파인튜닝을 통해 챗봇을 위한 '질문/대답' 데이터로 새롭게 학습을 합니다. 이렇게 하면 오히려 더 좋은 결과를 얻을 수 있다고 합니다.
우리 인간도 마찬가지로 이런 사전훈련이 중요합니다. 예를 들어, 영어를 전혀 모르는 호텔 직원이 외국인에게 안내하는 법을 배울때 그냥 무식하게 '질문/대답' 문장만 달달 외울 수 있습니다. 물론 계속 반복하다 보면 자연스럽게 그 뜻을 파악할 수도 있지만 그리 효과적이지 않습니다. 그보다는 간단한 영어문장부터 차근차근 읽어 영어의 기본을 익힙니다. 그 다음 '질문/대답' 문장을 외우면 더 빠르고 정확하게 학습이 가능합니다.
BERT에서 사용한 사전훈련의 첫번째 방법은 단어를 랜덤하게 마스킹하는 것입니다. 입력으로 특정 단어가 마스킹된 문장을 넣고 출력으로 마스킹 단어를 예측합니다.
<Input> = my dog is [MASK]
<Label> hairy
두번째는 입력으로 두개의 문장을 넣었을때 그것이 연속된 의미인지 판단합니다. 문장에서 마스킹도 같이 적용합니다.
<Input> = [CLS] the man went to [MASK] store [SEP] he bought a gallon [MASK] milk [SEP]
<Label> = IsNext
<Input> = [CLS] the man [MASK] to the store [SEP] penguin [MASK] are flight ##less birds [SEP]
<Label> = NotNext
사전훈련을 위해 위키피디아(25억단어)와 BooksCorpus(8억단어)를 사용했습니다. 그리고 학습이 끝난 모델의 마지막에 해당 문제를 위한 간단한 신경망 레이어를 붙여서 추가로 파인튜닝을 합니다. 이런 방법의 장점은 이미 사전훈련을 통해 언어모델이 만들어졌기 때문에 데이터셋이 적어도 학습이 쉽게 된다는 것입니다. 앞으로 자연어처리 분야에서 사전훈련이 핵심적인 역할로 떠오를 것 같습니다.