

- AI Dev - 인공지능 개발자 모임
- 정보공유
- 챗봇 딥러닝
글 수 283
시각화의 장인 Jay Alammar가 설명하는 GPT2입니다. 정말 쉽게, 그리고 매우 자세히 모델의 동작방식을 보여주고 있습니다. GPT2는 BERT와 마찬가지로 트랜스포머가 기반입니다. 다만 BERT는 트랜스포머의 인코더만 사용하는데 반해, GPT2는 디코만으로 구성됩니다. 예측한 토큰이 다시 입력으로 들어가며 반복해서 토큰을 생성하기 때문입니다. 이를 자동회귀(auto regression)라 부릅니다.
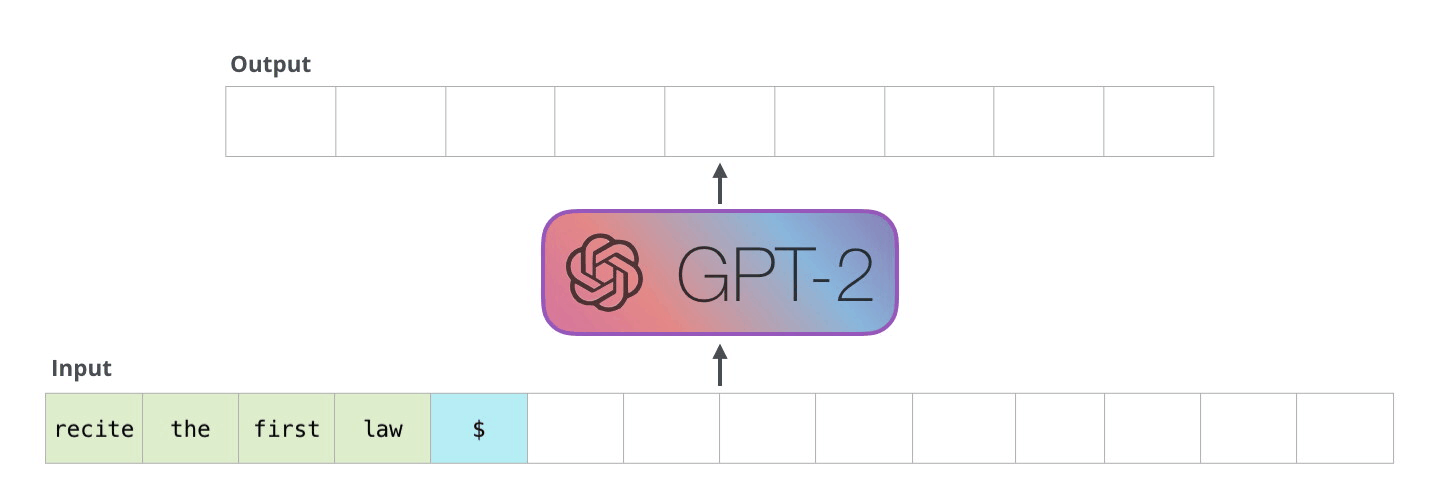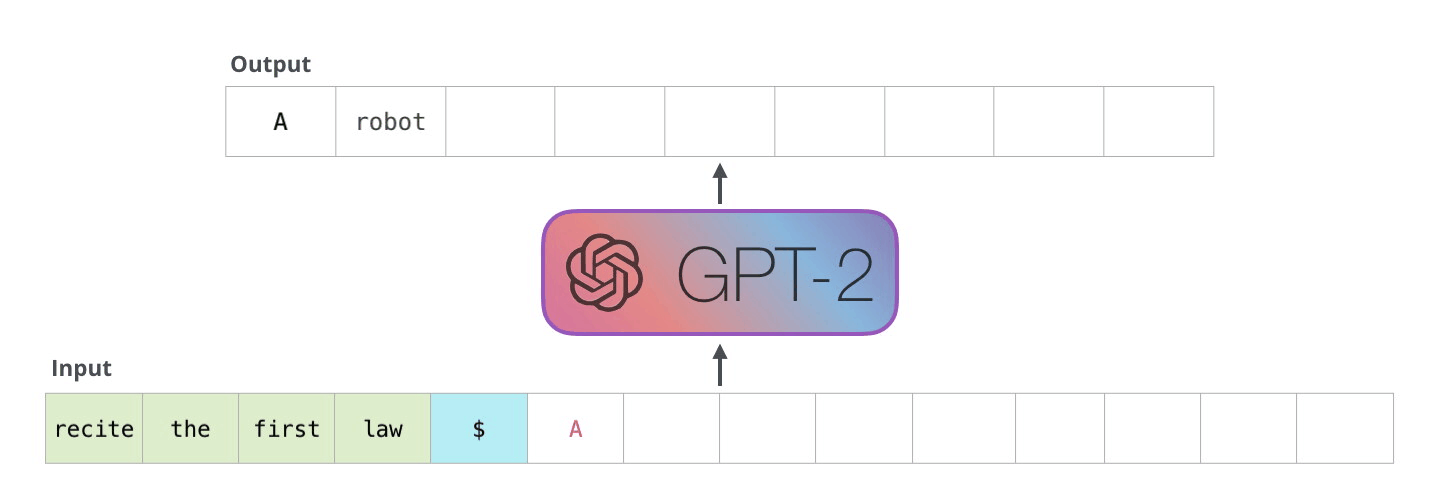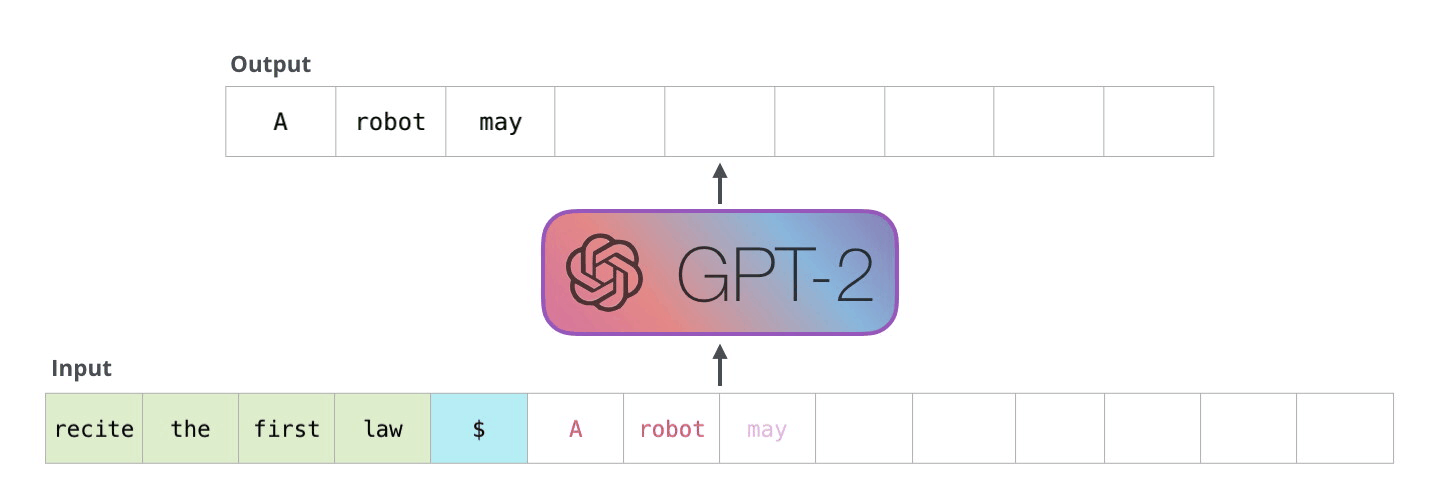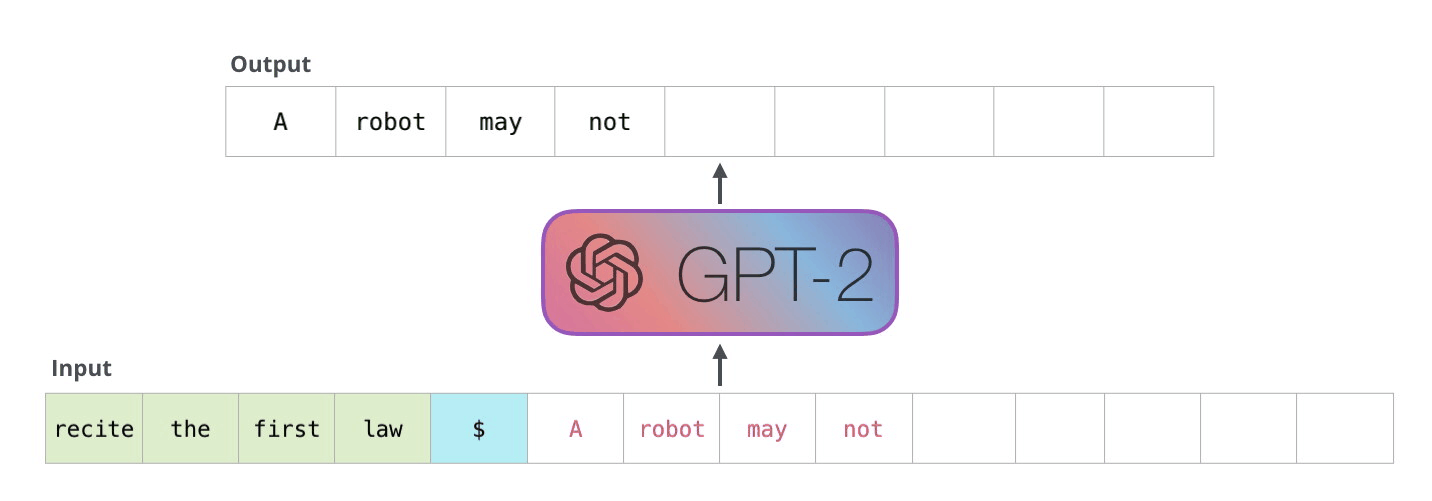
뒷부분에는 트랜스포머의 핵심인 셀프 어텐션(self-attention)을 다루고 있습니다. 이전 글(https://nlpinkorean.github.io/illustrated-transformer/)에서 빠져 있던 Masked self-attention이 추가되었습니다. BERT는 모든 입력 시퀀스 전체에 대해 셀프 어텐션을 수행합니다. 하지만 GPT2에서 같은 방법을 적용하면 문제가 발생합니다. 미리 앞에 나올 토큰을 볼 수 있어 답을 알고 맞추게 됩니다. 그래서 현재까지 예측한 토큰까지만 마스킹을 하여 셀프 어텐션을 합니다.
![]()
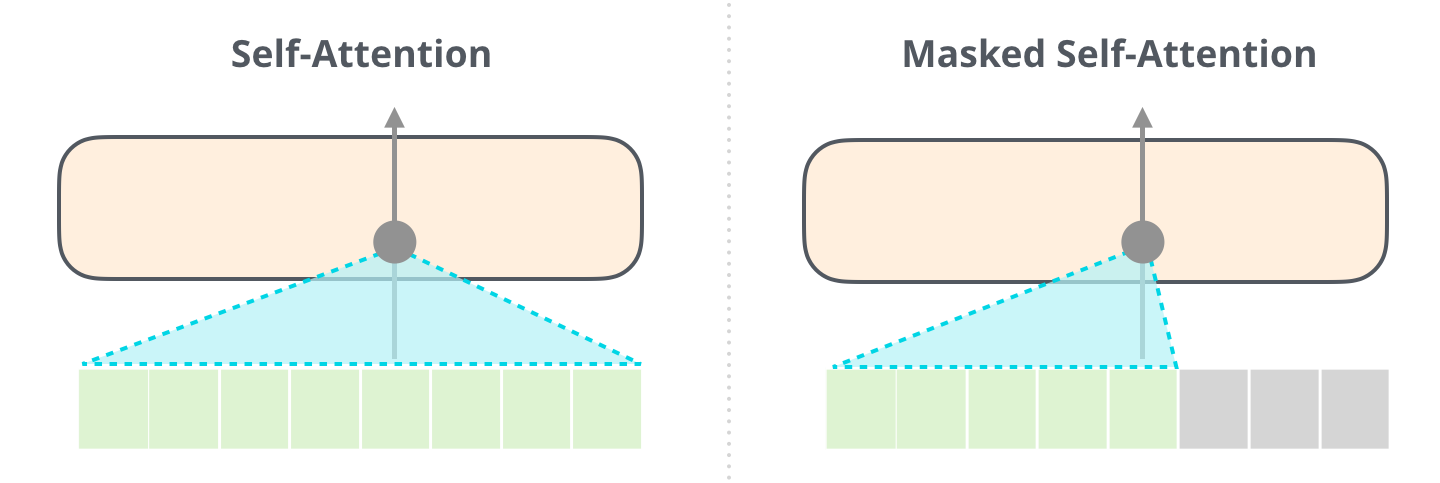
요즘 GPT3에 관심있는 분들이 많으실 텐데요. 거의 같은 구조이니 이 글을 참조하시기 바랍니다.
< The Illustrated GPT-2 >
- http://jalammar.github.io/illustrated-gpt2/