

- AI Dev - 인공지능 개발자 모임
- 정보공유
- 챗봇 딥러닝
스탠포드대에서 Alpaca라는 instruction 모델을 공개했습니다. 얼마 전 메타가 발표한 LLaMa 7B 모델을 파인튜닝했습니다. 놀라운 점은 7B Alpaca가 175B인 GPT-3.5(text-davinci-003)와 동급의 성능을 보인다는 것입니다. LLaMa 자체가 상당히 좋은 모델인데, 여기에 instruction 기법을 도입한게 주요했던 것 같습니다.
Instruction은 InstructGPT에서 처음 소개되었는데요. 보통 GPT는 auto-regressive라는 자기지도학습을 사용합니다. 위키피디아 같은 문서가 있으면 현재 문장을 입력으로 넣고 다음에 나올 단어를 계속 맞추는 방법입니다. 이렇게 하면 라벨링을 할 필요가 없다는 장점이 있습니다. 하지만 모델이 정확하게 내가 원하는 대답을 하게 만들기가 어렵습니다. RLHF(Reinforcement Learning from Human Feedback)은 여기에 사람의 노력을 더 추가하여 성능과 정확도를 높였습니다. 다음과 같은 3단계를 거칩니다.
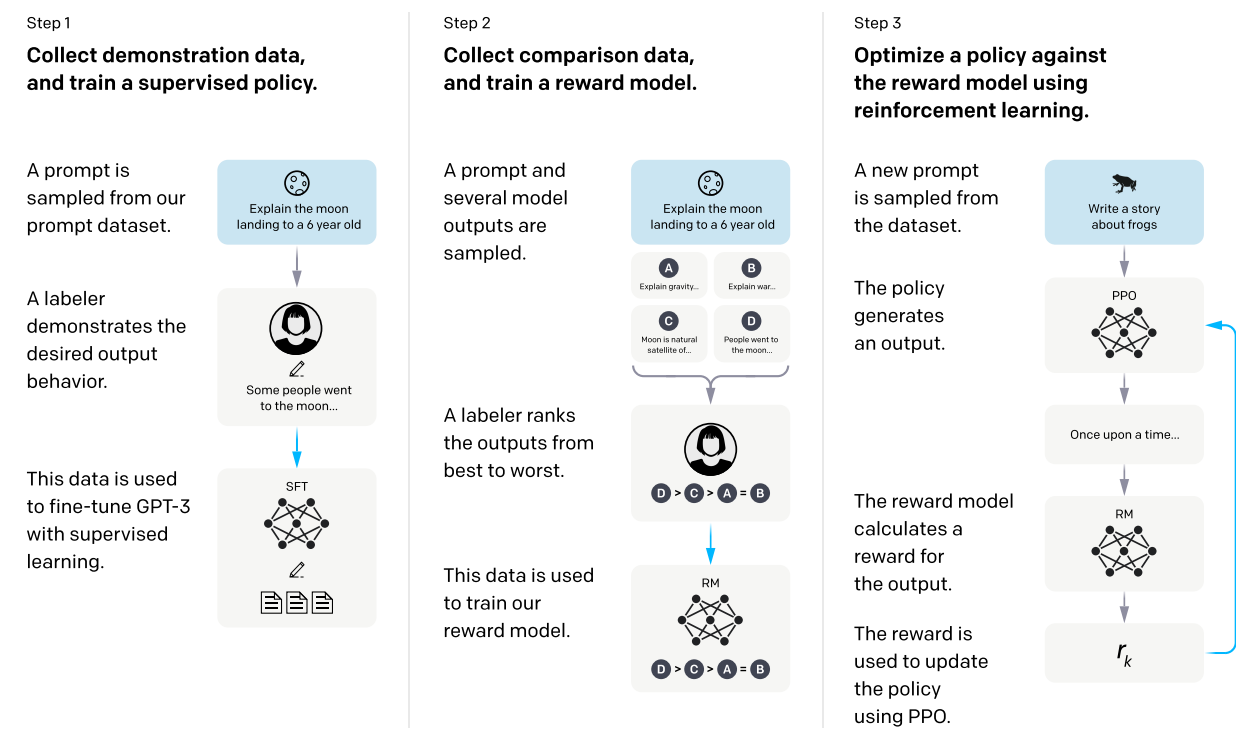
1단계. 질문 문장에 사람이 직접 대답을 작성합니다. 그리고 질문이 입력되면 사람의 대답이 출력되게 지도학습을 합니다.
2단계. 질문을 사전훈련된 여러 모델에 넣고 다양한 대답을 생성합니다. 사람이 이 대답을 좋은 순으로 순위를 매깁니다. 이 정보를 가지고 강화학습에 사용될 보상함수를 만듭니다.
3단계. 1단계에서 지도학습으로 파인튜닝한 모델을 베이스로 강화학습을 합니다. 이때 2단계에서 만든 사람의 피드백이 담긴 보상함수를 사용합니다.
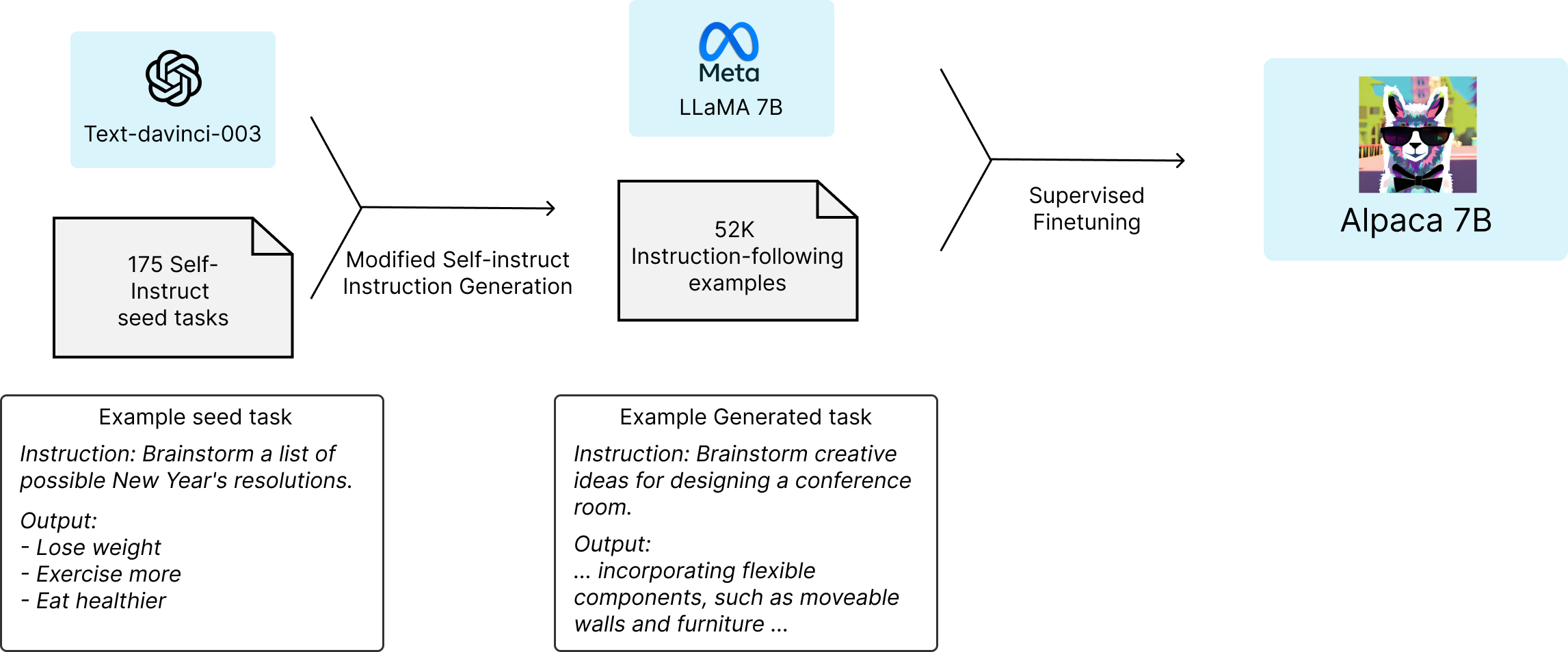
정확하지는 않지만 Alpaca는 강화학습은 쓰지 않은 듯 합니다. 위의 RLHF에서 1단계만 적용한 것으로 보입니다. 여기에 또 하나 주목할 만한 기법을 도입했습니다. instruction을 하기 위해서는 사람이 대답을 직접 작성해야 하는 문제가 있습니다. Alpaca는 이 과정을 자동화했습니다. 먼저 175개 대답만 사람이 만듭니다. 그리고 나머지는 질문과 대답 모두 text-davinci-003으로 생성했습니다. 총 52,000개의 데이터를 만들었다고 합니다.

앞으로 모델 크기는 작아지고 품질은 훨씬 높아진 LLM이 계속 등장할 것입니다. Stable Diffusion처럼 LLM도 오픈소스의 힘이 중요해질 세상이 될까요. ChatGPT로 시작된 변화에 점점 가속도가 붙고 있습니다. 내일은 또 어떤 새로운 소식이 등장할지 기대가 되네요.
< Alpaca 블로그 >
https://crfm.stanford.edu/2023/03/13/alpaca.html
< Alpaca 데모 >
https://crfm.stanford.edu/alpaca/