

- AI Dev - 인공지능 개발자 모임
- 정보공유
- 챗봇 딥러닝
https://jiho-ml.com/weekly-nlp-31/
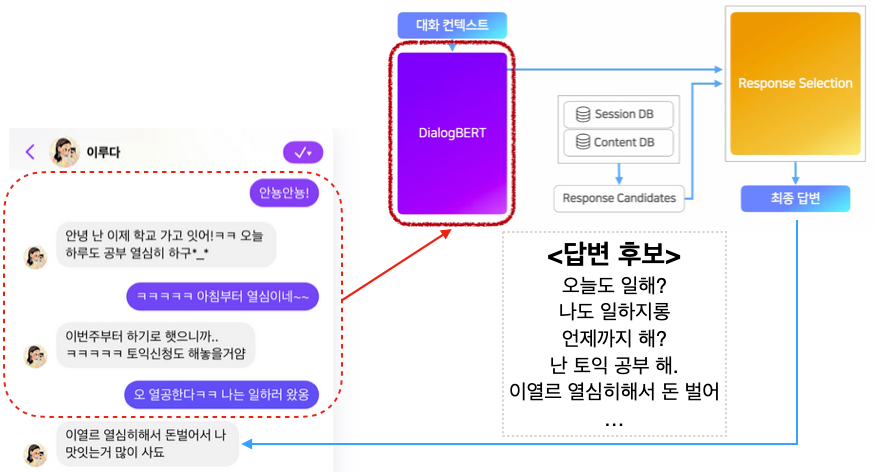
이루다의 작동 원리에 대한 글입니다. 챗봇은 크게 문장을 직접 생성하는 방식과 DB에서 적절한 문장을 찾아서 보여주는 방식으로 구분됩니다. 페이스북의 Blender, 구글의 Meena, OpenAI의 GPT-3(챗봇전용은 아니지만)가 생성 기반의 대표적인 모델입니다. 하지만 자연스러운 대답을 하려면 모델의 크기가 커야 되고, 그만큼 학습과 추론에 걸리는 비용이 높아집니다. 이루다는 후자의 방식을 사용하여 좀 더 효율적으로 챗봇을 구현했습니다.
우선 멀티턴 대화 구조로 수정한 DialogBERT를 사전훈련 합니다. 이렇게 만든 모델을 인코더로 사용하여 세션 문장(여러 턴의 이어진 문장들, Q1/A1/Q2)을 벡터로 변환합니다. 그리고 사용자가 입력한 세션 벡터와 DB에 있는 세션 벡터들을 코사인 유사도로 비교합니다. 이렇게 입력 세션과 가장 비슷한 후보 세션 문장들을 추려내는게 첫 번째 단계입니다.
그 다음으로 후보 세션에서 가장 높은 유사도를 가진 세션을 찾아 해당 답변(A2)을 선택할 수도 있습니다. 하지만 이렇게 하면 정확도가 많이 떨어집니다. 그래서 Reranker라는 새로운 모델로 후보 세션들에서 최종 답변을 선택합니다. 이 때 두 가지 방법이 있습니다.
하나는 Cross-Encoder입니다. BERT 같은 모델에 (현재 대화의 세션 + 후보 세션의 답변)를 묶어서 입력으로 넣습니다. 출력은 세션 다음에 답변 문장이 이어지는가의 확률입니다. 이렇게 하면 세션과 답변의 전체 문맥을 고려하여 정확도가 높습니다. 하지만 계산량이 너무 크다는 문제가 있습니다. 모든 후보 답변의 수만큼 새로 계산해야 되기 때문입니다.
다른 하나는 Bi-Encoder입니다. 말 그대로 인코더를 세션과 답변 두 개로 분리합니다. 그리고 각 인코더의 출력을 연결하여 최종 판단을 합니다. 답변 후보들은 미리 인코더를 사용하여 벡터로 계산해놓을 수 있습니다. 현재 대화 세션은 항상 변하기 때문에 그때마다 계산합니다. 대신 한 번만 인코더로 뽑아내어 모든 답변 후보에 공통으로 적용하면 됩니다. 아직까지는 속도 문제 때문에 Cross-Encoder보다 Bi-Encoder가 더 적합합니다. 이루다는 Bi-Encoder를 변형한 Poly-Encoder를 사용했다고 합니다.