

- AI Dev - 인공지능 개발자 모임
- 정보공유
- 챗봇 딥러닝
요즘 LLM에서 Merge와 DPO가 많이 쓰이고 있습니다. 얼마 전 공개된 업스테이지 SOLAR-10.7B도 이 두가지 기법을 사용했습니다.
Merge는 두 개 이상의 모델을 섞어서 하나의 모델로 만드는 방법입니다. SOLAR는 instruction tuning과 alignment tuning으로 학습한 모델들을 Merge하여 성능을 높였습니다. Merge는 학습이 아니기 때문에 CPU 계산만으로 매우 빠르게 수행할 수 있다는 장점이 있습니다.

DPO(Directly Preference Optmization)는 RLHF(Reinforcement Learning from Human Feedback)를 대체할 수 있는 방법입니다. RLHF는 같은 질문에 대해 여러 LLM의 대답 중 사람이 선택한 데이터로 보상 함수를 만듭니다. 그리고 보상 함수로 강화학습을 수행하여 모델 성능을 향상시킵니다. DPO 역시 선호 데이터를 사용하지만 보상 함수 없이 바로 학습을 합니다.
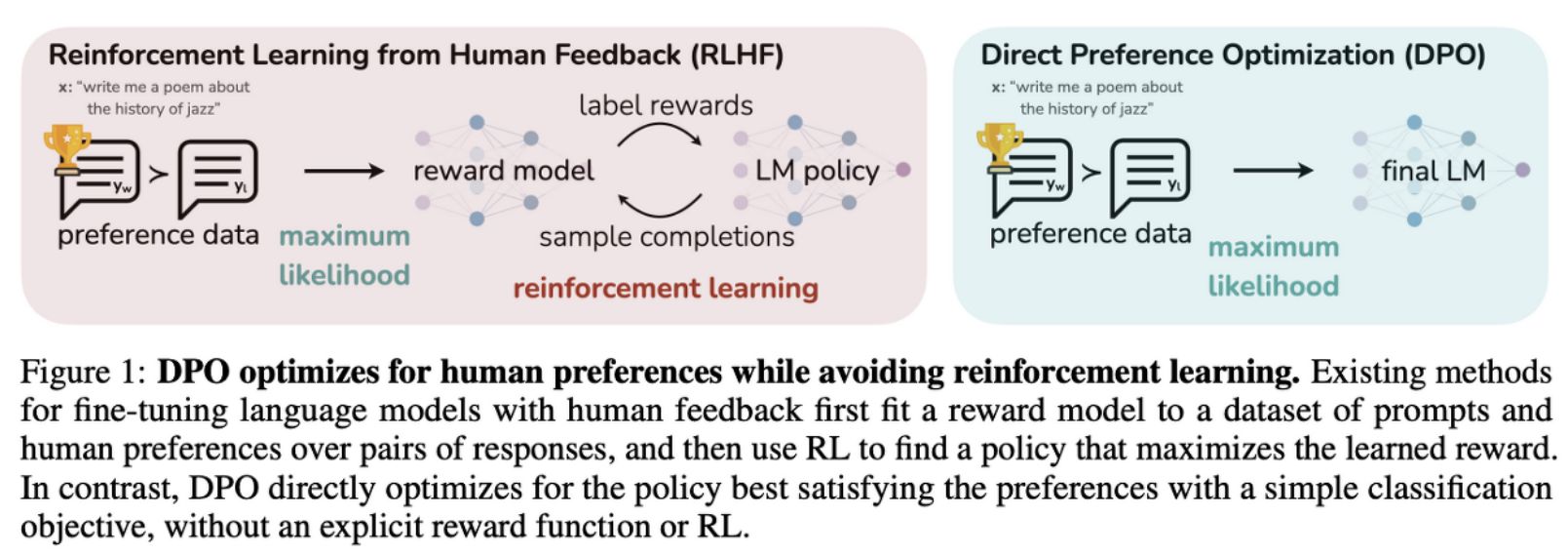
요즘 리더보드에 이 두가지 방법을 통해 높은 순위를 얻는 경우가 많아지고 있습니다. 대표적으로 Sakura-SOLAR-Instruct가 있습니다. 먼저 SOLAR-10.7b-Instruct-v1.0와 SauerkrautLM-SOLAR-Instruct 모델을 Merge합니다. 다음으로 다양한 DPO 데이터셋을 사용해서 DPO 학습을 했습니다. 이 과정만으로 리더보드 1위를 달성했다고 합니다.
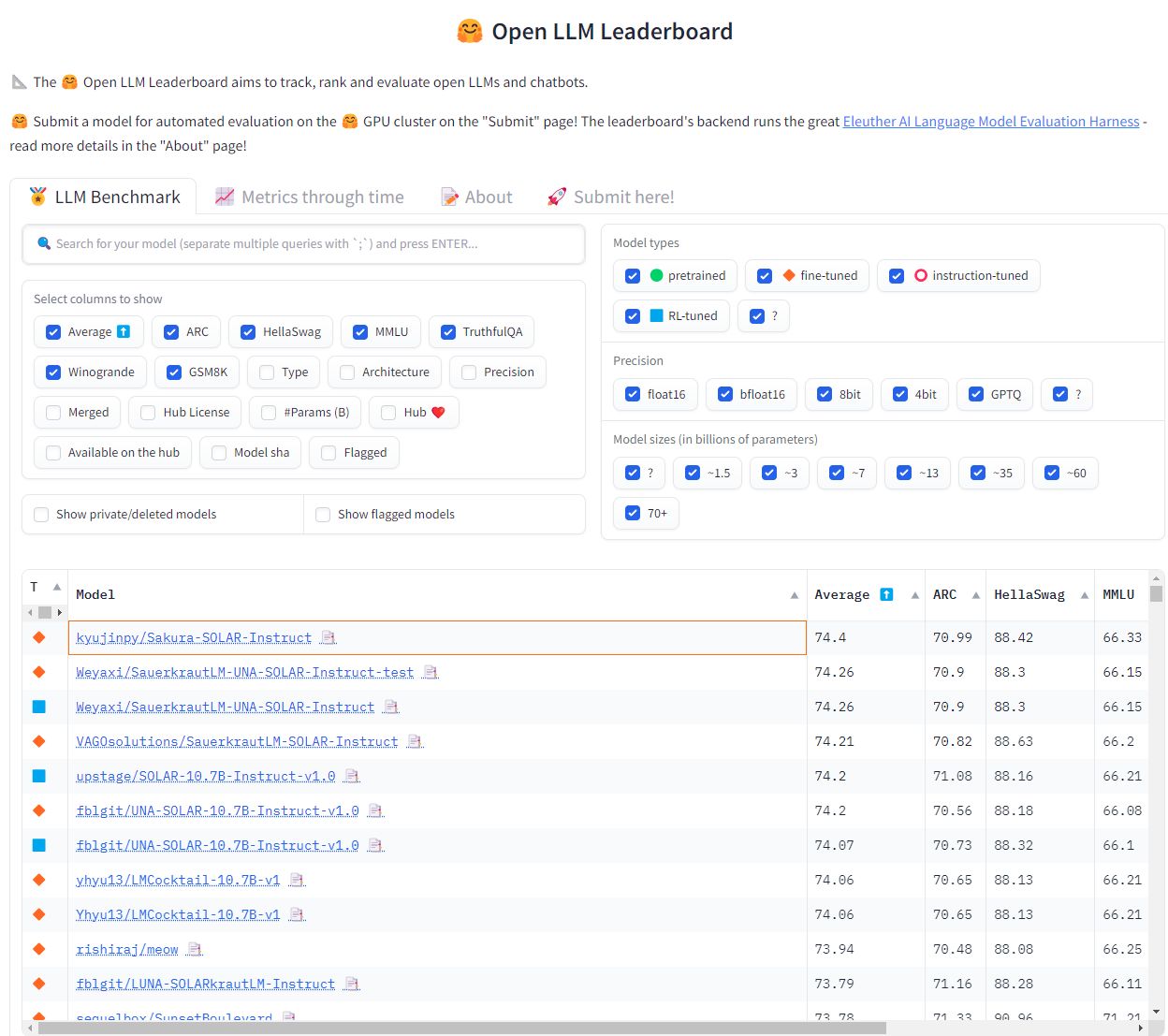
예전 머신러닝 시절에는 여러 모델을 앙상블하여 하나의 결과를 내는 방식이 주로 쓰였습니다. Merge도 약간 비슷한 느낌이 드네요.
< MergeKit >
https://github.com/cg123/mergekit
< Sakura-SOLAR >
https://kyujinpy.tistory.com/122
< DPO 논문 리뷰 >
https://hi-lu.tistory.com/entry/Paper-DPO-%EB%85%BC%EB%AC%B8-%EB%A6%AC%EB%B7%B0