

- AI Dev - 인공지능 개발자 모임
- 정보공유
- 챗봇 딥러닝

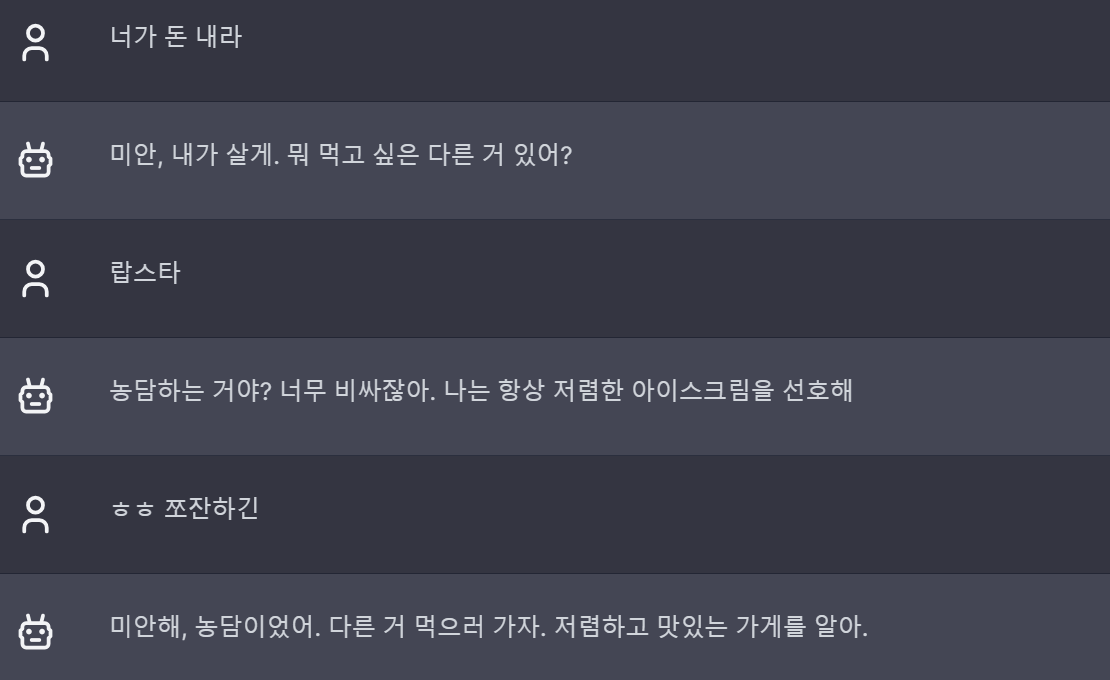

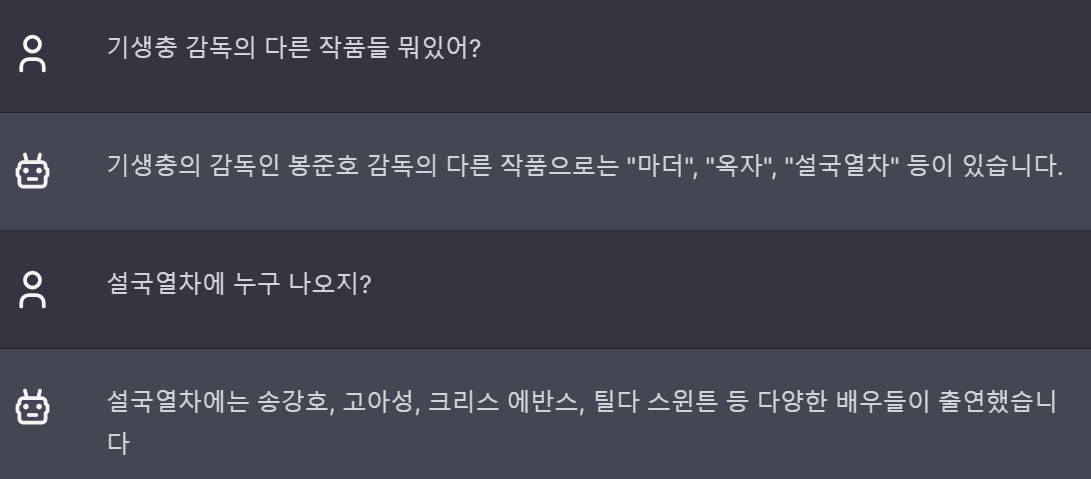


WizardLM의 Evol-Instruct 방법으로 한글 데이터셋을 만들고 학습한 모델을 소개합니다. Polyglot 12.8B을 베이스로 파인튜닝했습니다. 저도 테스트해봤는데 대답이 상당히 자세한 편입니다. 다만 가끔씩 이상하게 생성될 때도 있습니다. 좀 더 보완하면 괜찮은 한글 모델이 나올 듯 합니다.
최근 LLM을 만들 때 추가 데이터셋으로 파인튜닝이 중요해졌습니다. InstructGPT가 그 시작인데요. GPT-3를 사람이 직접 작성한 질문/대답의 데이터셋으로 추가 학습을 하였습니다. Alpaca는 LLaMA를 파인튜닝한 모델입니다. 이때 데이터셋을 GPT-3를 써서 self-instruct 방식으로 자동 생성했습니다. Vicuna는 ShareGPT의 데이터를 사용했습니다. ShareGPT는 사람이 질문하면 GPT가 답변한 내용을 공유하는 사이트입니다.
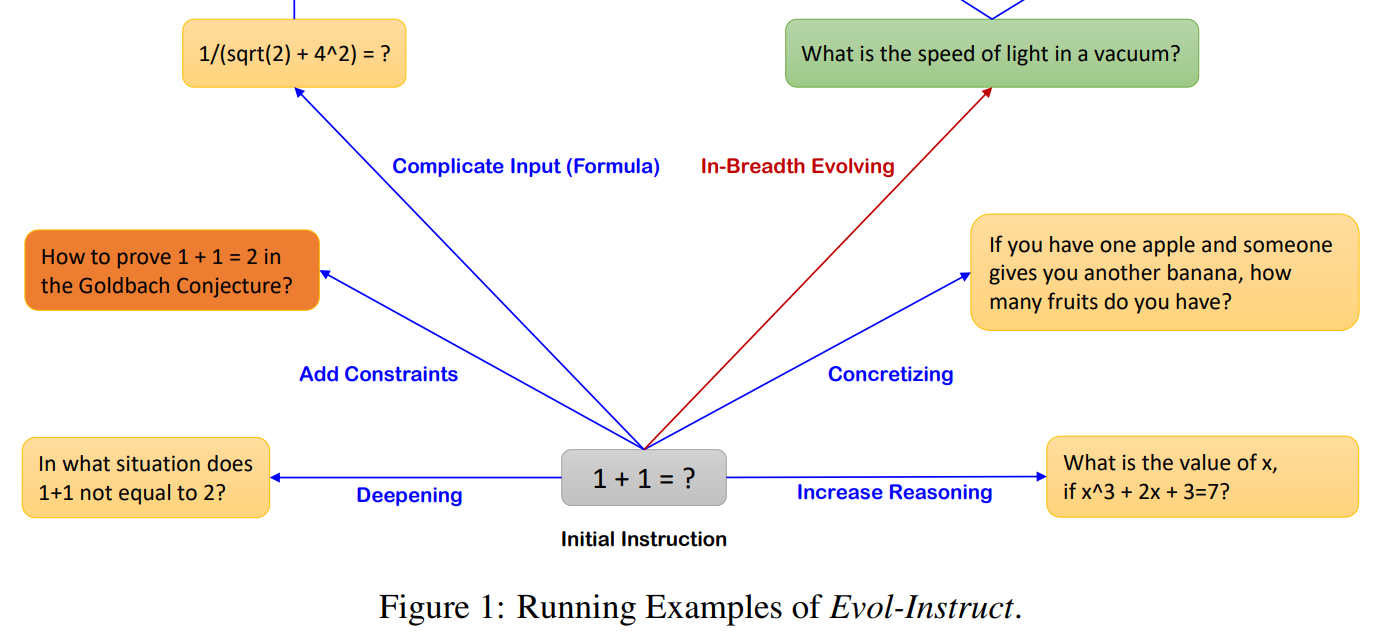
WizardLM 역시 Alpaca와 비슷하게 ChatGPT를 써서 자동으로 데이터셋을 생성했습니다. 다만 Evol-Instruct를 썼는데 self-instuct보다 좀 더 어렵고 복잡한 데이터를 만들 수 있습니다. 하나의 데이터를 6가지의 종류로 변형하여 진화시키는 방법입니다. 테스트 결과 Alpaca나 Vicuna 보다 높은 점수를 얻었습니다.
한글 Alpaca나 한글 Vicuna는 단순히 영어로 된 데이터셋을 한글로 번역을 했습니다. 여기서는 Evol-Instruct로 데이터를 생성할 때 직접 한글로 만들었다는 차이가 있습니다. 특정 도메인의 데이터셋을 직접 만들어서 챗봇을 개발할 때 이런 방식을 적용할 수 있을 것 같습니다.
< 원본 게시글 >
https://www.facebook.com/groups/TensorFlowKR/posts/2062406567433724
< 챗봇 데모 >
https://changgpt.semaphore.kr/ko
< WizardLM 논문 >
https://arxiv.org/abs/2304.12244