

- AI Dev - 인공지능 개발자 모임
- 정보공유
- 챗봇 딥러닝
https://tomaszurbanski.substack.com/p/the-hidden-price-tag-on-gpt-4-for
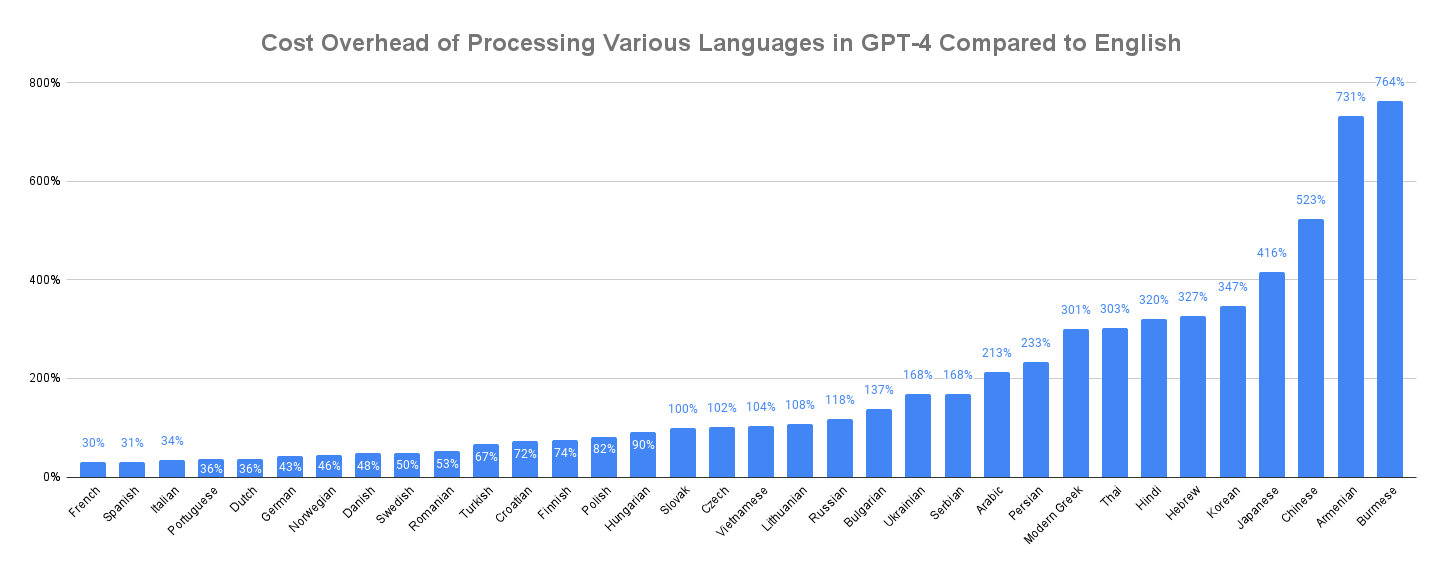
GPT-4에서 영어 대비 언어별 오버헤드를 정리한 표입니다. 한국어, 일본어, 중국어가 가장 하단에 있네요. 영어에 비해 거의 3배 정도 느립니다. 그만큼 같은 내용일 경우 비용도 더 증가하고요.
이는 GPT의 토크나이저가 BPE(Byte-Pair Encoding)에 기반하고 있기 때문입니다. 처음에는 캐릭터로 분리되지만 데이터셋에서 자주 나오는 캐릭터들은 하나의 토큰으로 합쳐집니다. 예를 들어, 처음에는 a, b, c, ..., z로 시작합니다. 만약 cat이 많이 보인다면 c, a, t가 붙어서 cat이 새로 토큰에 추가됩니다.
c, a, t보다 cat이 더 유리한 점이 무엇일까요. 바로 입력의 길이가 줄어들기 때문에 속도가 더 빨라진다는 것입니다. 그만큼 하나의 토큰이 더 많은 의미를 담게 되는 것이죠. 한중일 언어가 느린 이유는 이렇게 합쳐진 토큰이 적기 때문입니다. 아마 한중일의 데이터가 적어서일 것입니다. 데이터가 부족하면 빈도수가 낮고, 빈도수가 낮으면 토큰이 합쳐지지 않습니다.
그럼 10만개가 아니라 100만개로 토큰 최대치를 늘리면 되지 않을까요. 데이터가 적은 언어들도 토큰이 합쳐질 수 있게요. GPT에서 Transformer의 가장 마지막에는 Softmax 레이어가 있습니다. 여기서 최종적으로 출력되는 토큰을 결정합니다. 만약 토큰 최대치가 100만개라면 Softmax 역시 100만개 중 하나를 선택해야 합니다. 당연히 모델의 성능이 떨어질 수밖에 없습니다. 앞으로 기술이 더 개선되면 모르겠지만 현재로서는 무작정 토큰 최대치를 늘릴 수가 없습니다.
이와 별도로 한국어 콘텐츠가 부족하다는 점도 문제가 될 수 있습니다. 물론 영어나 다른 언어로 학습한 데이터도 한글로 물어보고 한글로 대답을 얻을 수 있습니다. 하지만 한국어 데이터가 적기 때문에 그만큼 한국 콘텐츠에 대해서 정확히 대답하기가 어렵습니다. 속도와 데이터, 이 2가지 면에서 한국어 전용 초거대AI가 어느정도 경쟁력을 가질 수 있다고 봅니다. 몇 년 후에는 또 어떻게 바뀔지 모르겠지만요.