

- AI Dev - 인공지능 개발자 모임
- 정보공유
- 챗봇 딥러닝
GPT2에서 문장을 생성 시, 마지막에 레이어를 하나 더 붙여 소프트맥스로 출력합니다. 단어사전에 1만개의 단어가 있다면, 각 단어의 확률값이 나옵니다. 이때 어떤 방법으로 단어를 선택할지에 대한 글입니다.
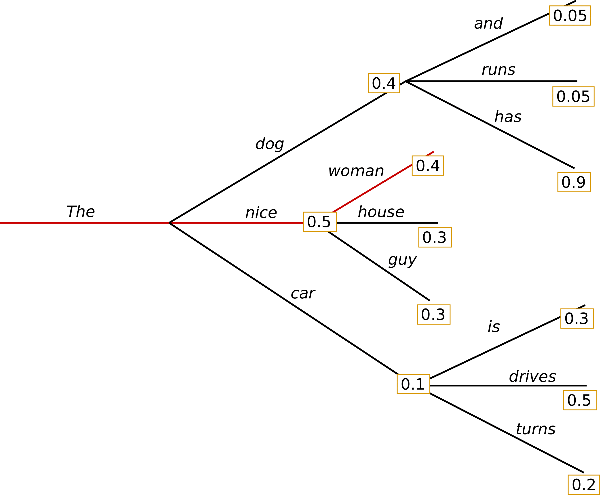
첫 번째는 Greedy Search입니다. 말 그대로 가장 높은 확률의 단어 하나만 고릅니다. 간단하지만 큰 단점이 존재합니다. 선택되지 않은 단어 다음에 더 높은 확률의 단어가 있을 경우 찾을 수가 없습니다. 아래 그림을 보면 The-nice-woman(0.5x0.4=0.2)보다 The-dog-has(04x0.9=0.36)의 확률이 더 큽니다. 그러나 처음 단어만 보고 분기를 결정한다는 문제가 있습니다.
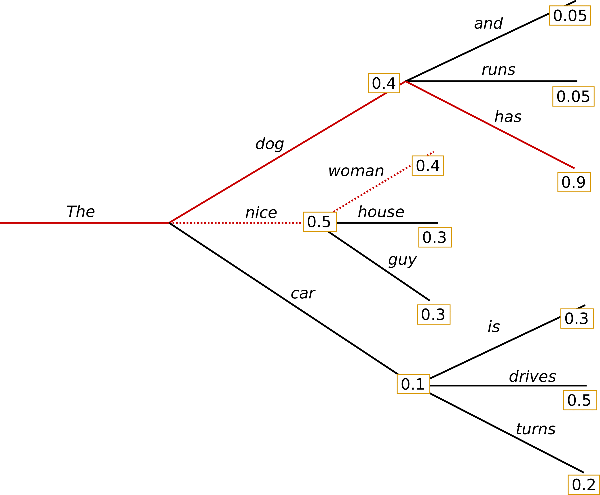
두 번째는 Beam Search입니다. 레이저를 쏘는 것처럼 빔을 확률에 따라 여러 가닥으로 분기합니다. 그 중에서 연속적인 단어 확률의 곱이 가장 높은 것을 선택합니다. Greedy Search의 문제를 보완할 수 있다는 장점이 있습니다. 다만 무조건 확률이 높은 것을 고르는게 좋지는 않습니다. 사람의 경우 잘 안쓰는 단어도 사용하면서 흥미로운 문장을 만들기 때문입니다.
세 번째는 Sampling입니다. 전체 단어의 확률값 만큼 랜덤하게 선택합니다. 그래서 판에 박히지 않은 글을 작성할 수 있습니다. Temperature라는 기법을 쓰면 좀 더 정교하게 조작이 가능합니다. 온도가 높으면 자유롭게, 온도가 낮으면 고정적으로 글을 작성합니다.
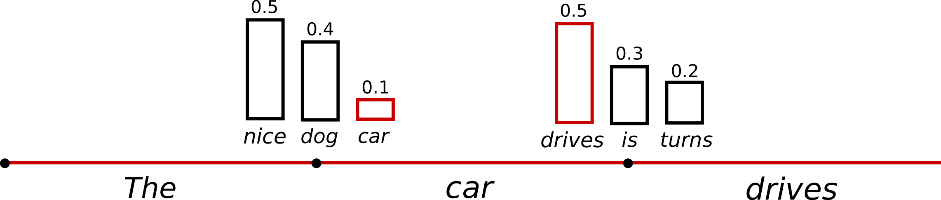
네 번째는 Top-K sampling입니다. 일반 Sampling은 확률이 아주 낮은 단어가 나올 수도 있습니다. 그래서 K개 만큼 확률의 높은 순서의 단어들만으로 제한을 둡니다. 아주 엉뚱한 단어가 나타나는 것을 방지합니다.
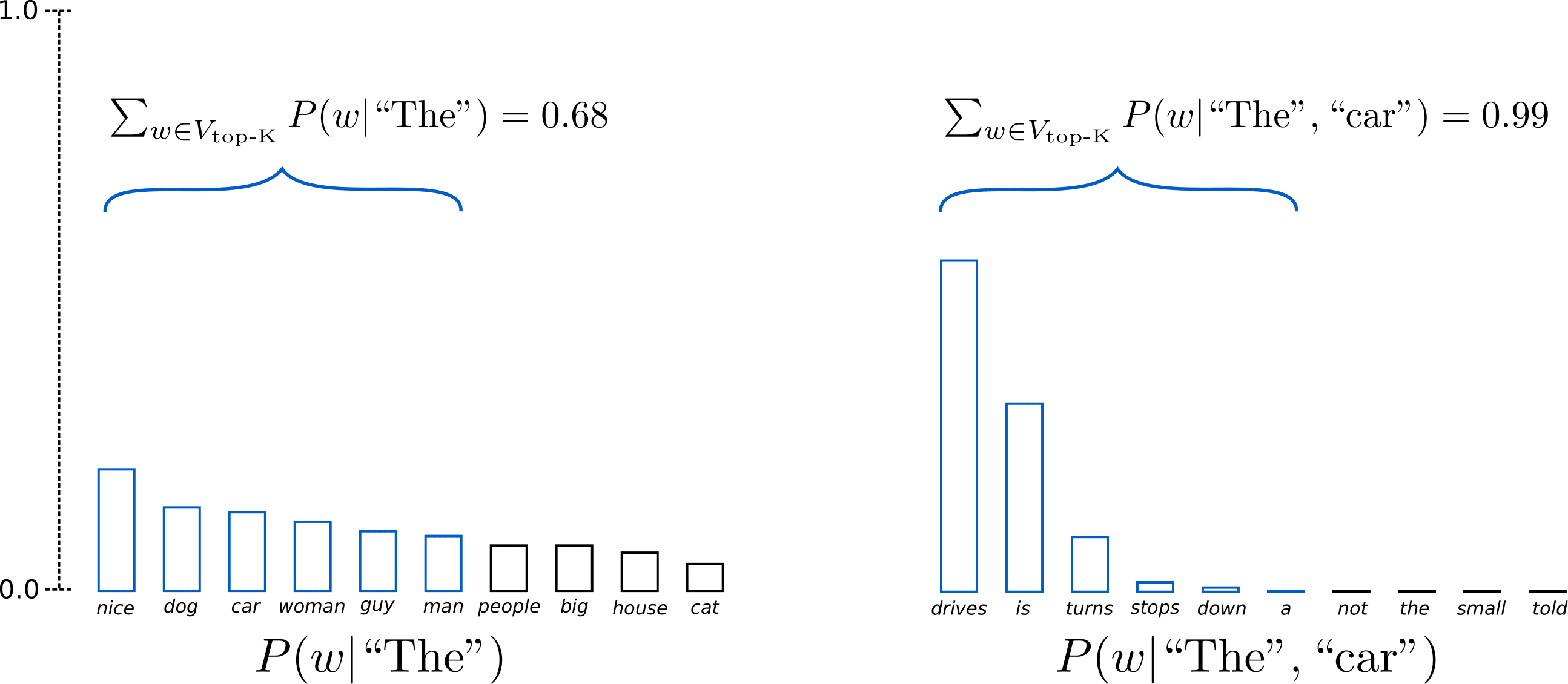
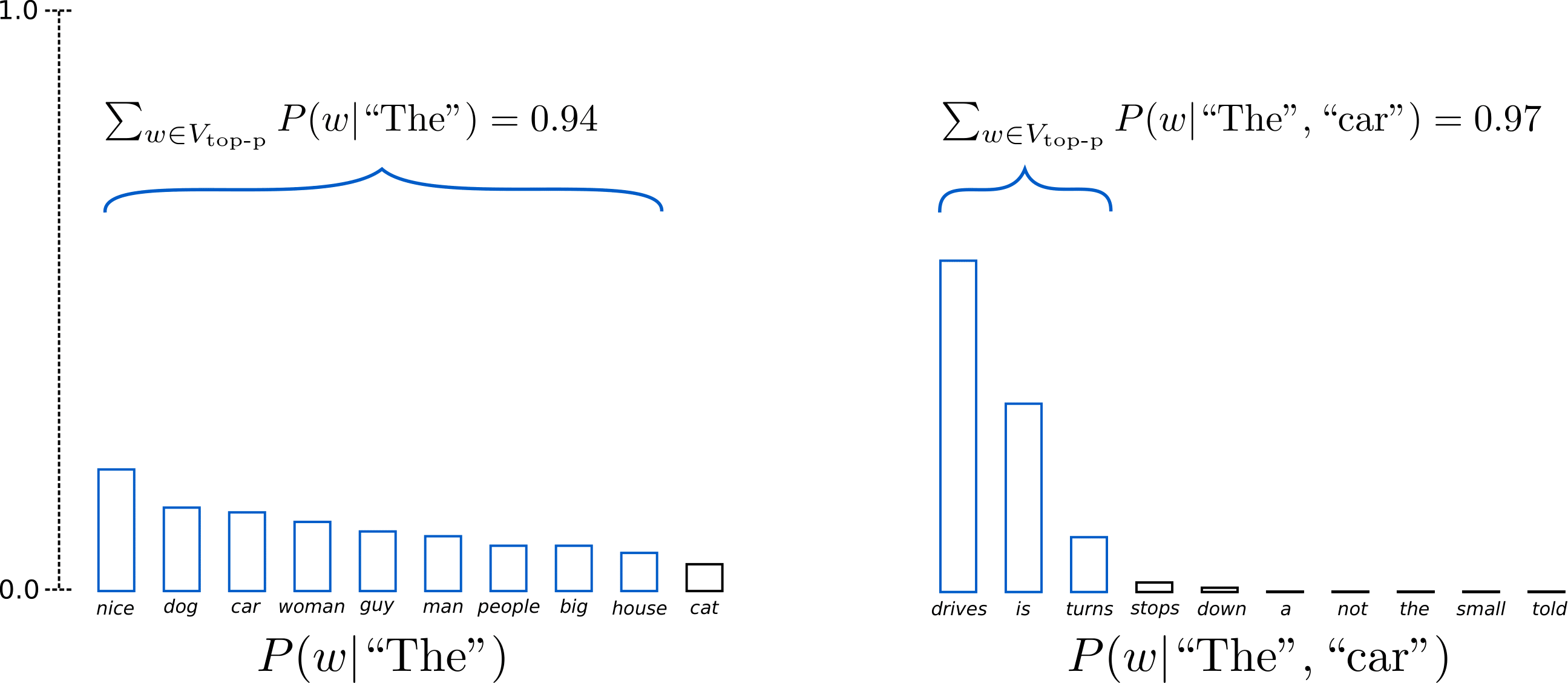
다섯 번째는 Top-p sampling입니다. Top-K의 경우 문제가 하나 있습니다. 단어의 확률이 어느 지점에서 급격하게 떨어지는 경우도 있습니다. 그러면 K개로 해도 아주 작은 확률의 단어가 선택될 가능성이 있습니다. 이를 해결하기 위해 합계 확률 p를 넘는 단어만 후보에 넣습니다. 예를 들어, p가 0.92라고 생각해보겠습니다. 확률이 큰 순서로 계속 단어의 확률을 더하다가 합계가 0.92를 넘으면 중단합니다. 이 후보들만 가지고 샘플링을 하면, 낮은 확률의 단어를 제외시킬 수 있습니다.
허깅페이스가 모델만이 아니라 글도 정말 쉽게 잘쓰네요. 덕분에 딥러닝 자연어처리를 구현하는게 훨씬 편해졌습니다.
< Using different decoding methods for language generation with Transformers >
-> https://huggingface.co/blog/how-to-generate