

- AI Dev - 인공지능 개발자 모임
- 정보공유
- 챗봇 딥러닝
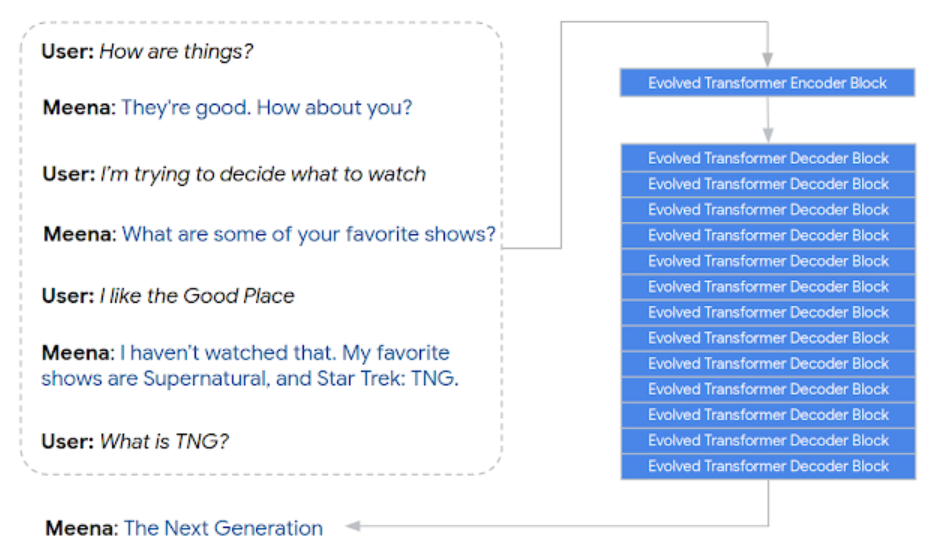
Reformer가 나온지 얼마 되지도 않았는데, 구글이 또 엄청난 모델을 공개했습니다. Meena란 이름의 일상대화 딥러닝 모델로 Evolved Transformer를 사용했습니다. AutoML 처럼 자동으로 트랜스포머의 구조를 결정하는 방식입니다. 사진과 같이 인코더 블록 1개와 디코더 블록 13개로 되어 있습니다. End-to-End로 문장을 생성할때는 디코더가 더 중요한 역할을 한다고 합니다.
우선 모델 파라미터가 2.6B으로 GPT2의 1.5B보다 1.7배 더 커졌습니다. 학습 데이터도 361GB로 GPT2의 40GB보다 8배 이상 많습니다. 7개의 문장의 멀티턴 대화 질문과 그다음 답변으로 구성된 페어 8억개 정도로 훈련을 했습니다. TPU-v3 2048개 코어로 30일 동안 돌렸는데요. 구글 클라우드 가격으로 대충 계산해보니 13억이 듭니다. XLNet이 TPU-v3 512개 코어 x 3일 = 6천만원이란걸 비교해보면 무지막지한 모델입니다.
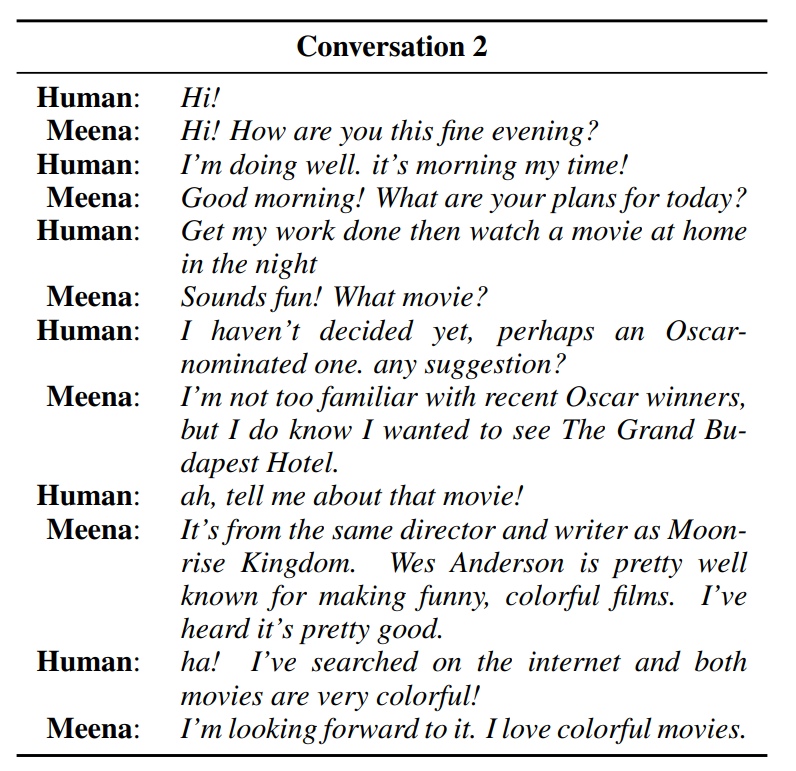
위의 대화 예시를 보면 문맥을 고려하여 상당히 자연스럽게 대답을 하고 있습니다. 또한 단순히 맞장구 치는 것을 넘어서, 영화란 콘텐츠에 맞게 구체적인 내용을 알려줍니다.
사람 : 오스카 후보로 오른 영화가 어떨까. 하나 추천해줄래?
Meena : 최근 오스카 수상작들은 잘 모르는데. 하지만 그랜드 부다페스트 호텔이란 영화를 보고 싶었어.
사람 : 아, 그 영화에 대해서 더 말해줘봐.
Meena : 문라이즈 킹덤과 같은 감독과 작가야. 웨스 앤더슨은 재미있고 컬러풀한 영화로 매우 유명해. 매우 좋은 작품이라고 들었어.
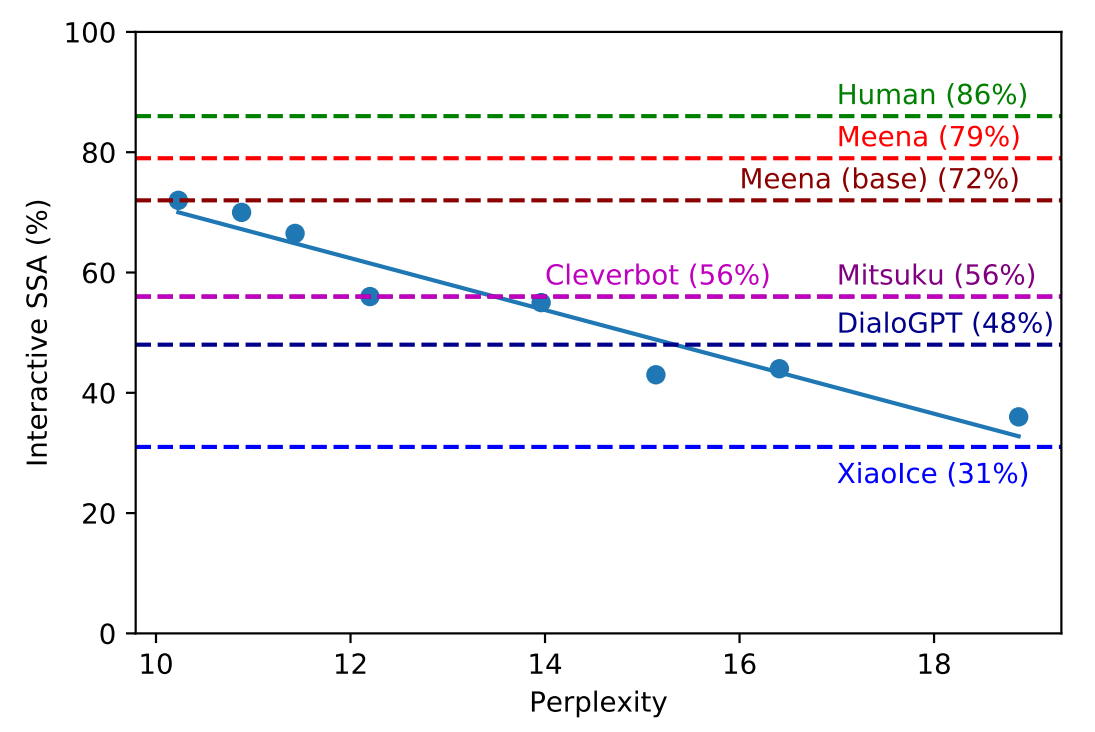
이런 생성 모델은 평가 기준이 상당히 애매한 편입니다. 이를 위해 SSA(Sensibleness and Specificity Average)라는 새로운 방법을 제시합니다. 모델의 대화 결과를 사람이 직접 평가를 합니다. Sensibleness는 말이 이어지는지 판단합니다. 여기에 Specificity라는 항목을 같이 고려합니다. '잘모르겠는데', '그래서?', '맞아' 같이 두리뭉실한 대답보다 좀 더 구체적인 문장에 더 높은 점수를 부여합니다.
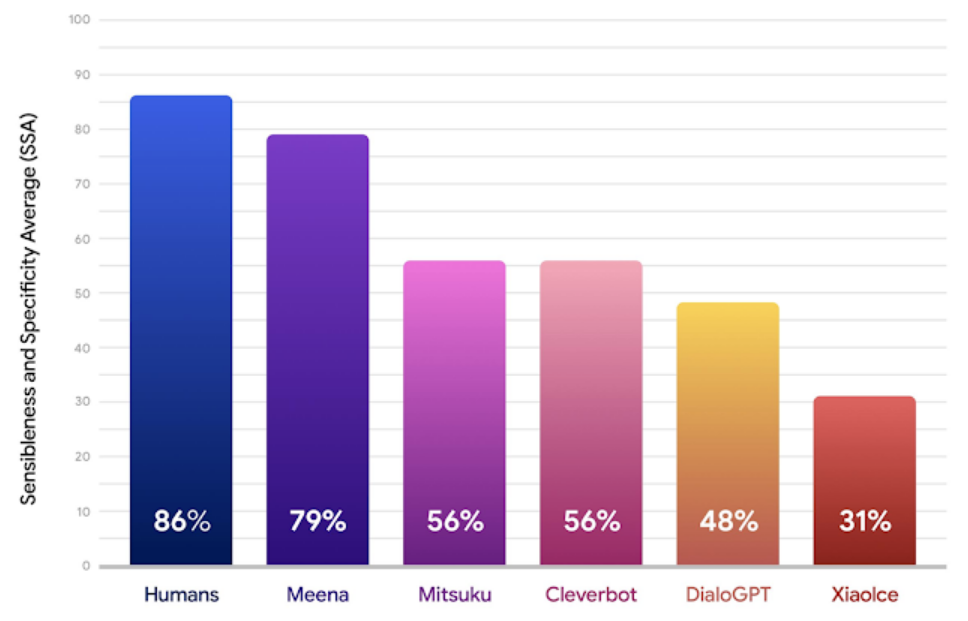
Mitsuku, Cleverbot, DialGPT, XiaoIce 같은 다른 챗봇보다 Meena의 SSA가 월등히 뛰어납니다. 또한 자동화된 평가방법으로 가장 유명한 Perplexity와도 비교를 했습니다. 그래프를 보면 사람이 측정한 SSA와 수식으로 계산한 Perplexity의 상관관계가 높음을 알 수 있습니다. 이후 대화 시스템을 평가할때 좋은 기준이 될 것 같습니다.
그동안 챗봇은 거의 룰베이스 유사도와 통계 방식을 기반으로 했습니다. 의도를 먼저 분류하고 거기에 맞는 템플릿 문장을 출력합니다. Seq2Seq로 대답 문장을 직접 생성하기도 하지만 아직까지는 거의 사용되지 않습니다. Meela의 성능을 보니 이제 대화 서비스도 End-to-End로 바뀔 날이 얼마 남지 않은 듯 합니다. 다만 데이터가 적을 경우 딥러닝으로 학습이 힘들다는 문제가 있습니다. 이것도 전이학습 같은 방법을 적용하면 충분히 극복할 수 있다고 생각합니다. 당장은 어렵겠지만 앞으로 3~5년이면 큰 변화가 오지 않을까요.
< 구글 블로그 >
-> https://ai.googleblog.com/2020/01/towards-conversational-agent-that-can.html
< 논문 >