

- AI Dev - 인공지능 개발자 모임
- 정보공유
- 챗봇 개발
https://songys.github.io/2019LangCon/data/DIY.pdf
오늘 바벨TOP 세미나를 갔다왔습니다. 그중 박혜웅님의 <DIY 챗봇>을 소개해 드리겠습니다.
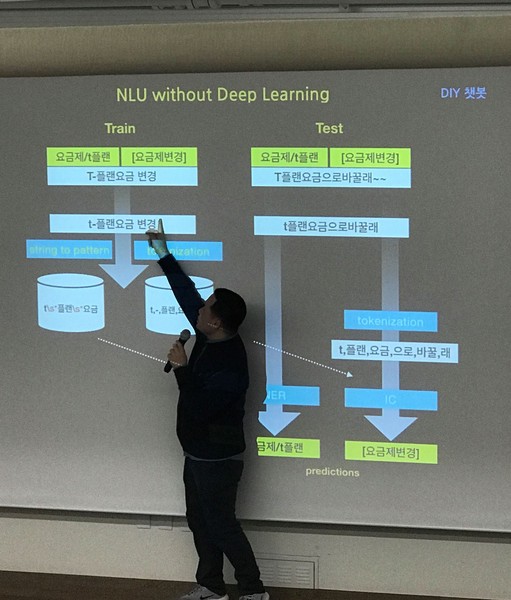
보통 챗봇 빌더에서 의도 파악을 위해 가장 많이 쓰는 방법은 확률/통계 기반의 나이브 베이즈입니다. 입력 문장에 대해서 각 의도마다 확률을 구하고 가장 높은 확률의 의도를 선택합니다.
< 데이터셋 >
피자 보내줘 -> 주문
피자 주문할래 -> 주문
피자 뭐있어? -> 정보
피자 메뉴 알려줘 -> 정보
< 의도 파악 >
P(주문|피자 주문) = P(피자 주문|주문) * P(주문) = 0.8 (높은 확률!)
P(정보|피자 주문) = P(피자 주문|정보) * P(정보) = 0.2
문장이 주어졌을 때 의도의 확률은 구하기 어렵습니다. 하지만 각 의도마다 문장이 나타날 확률은 데이터셋을 통해 계산할 수 있습니다. 여기에 TF-IDF를 써서 자주 나오고 중요하지 않은 단어의 가중치를 낮춥니다.
발표 내용에서는 이와 다르게 유사도 기반의 방식을 사용했습니다. 입력 문장을 토큰으로 쪼개고 의도로 설정한 문장과 일치하는 토큰의 개수를 구합니다. 마찬가지로 TF-IDF로 단어의 중요도에 따라 유사도를 조정합니다.
< 의도 문장 설정 >
피자 보내줘 -> 주문
피자 메뉴 알려줘 -> 정보
< 의도 파악 >
입력 문장 -> 피자 보내줘
(의도) 피자 보내줘 : 피자 보내줘 -> 토큰일치 2 (높은 유사도!)
(정보) 피자 보내줘 : 피자 메뉴 알려줘 -> 토큰일치 1
유사도를 비교하기 위해 오픈소스 검색엔진인 엘라스틱서치를 사용했다고 합니다. 직접 알고리즘을 구현할 수도 있지만 사용자가 많을 경우 검색엔진을 쓰는게 훨씬 빠르고 안정적입니다.
통계기반의 경우 같은 의도에 있는 여러 문장의 단어들을 조합하기 때문에 어느 정도 일반화가 된다는 장점이 있습니다. 예를 들어, Dialogflow에서 다음과 같이 테스트를 해봤습니다.
< 발화패턴 >
알람 맞춰
시간 설정
< 의도 파악 >
알람 맞춰 -> 성공
시간 설정 -> 성공
알람 설정 -> 성공
시간 맞춰 -> 성공
유사도 비교일 때는 각 문장 단위로만 검사를 합니다. 그래서 '알람 설정'이나 '시간 맞춰'처럼 같은 의도에 있는 다른 문장의 단어들이 조합되면 인식을 못합니다. 통계적 방식의 장점일 수도 있지만 '맞춰 설정' 같은 틀린 문장도 선택된다는 문제가 생깁니다. 정확도를 위해서는 오히려 유사도 기반이 더 나을 수도 있습니다.
실제로 밑바닥부터 챗봇을 구현하는데 있어 이런 유사도 방식도 효과적이라고 생각합니다. 유사도, 확률/통계, 딥러닝 중 어떤 알고리즘이 자신의 프로젝트에 적당할지 고민이 필요할 것 같습니다.