




OpenAI의 CLIP은 이미지와 텍스트를 동시에 고려하는 멀티모달 모델입니다. 이를 활용한 다양한 애플리케이션이 등장하고 있는데요. 이번에는 Text2Art란 사이트가 생겼습니다. 말로 설명하면 그림을 그려주는 서비스입니다.
DALL-E와 비슷하지만 동작방식에 차이가 있습니다. DALL-E는 GPT-3에 텍스트를 넣어 다음 픽셀을 예측합니다. 그 픽셀은 텍스트와 함께 다시 입력으로 들어갑니다. 이렇게 계속 반복적으로 예측하면서 전체 이미지를 생성합니다.
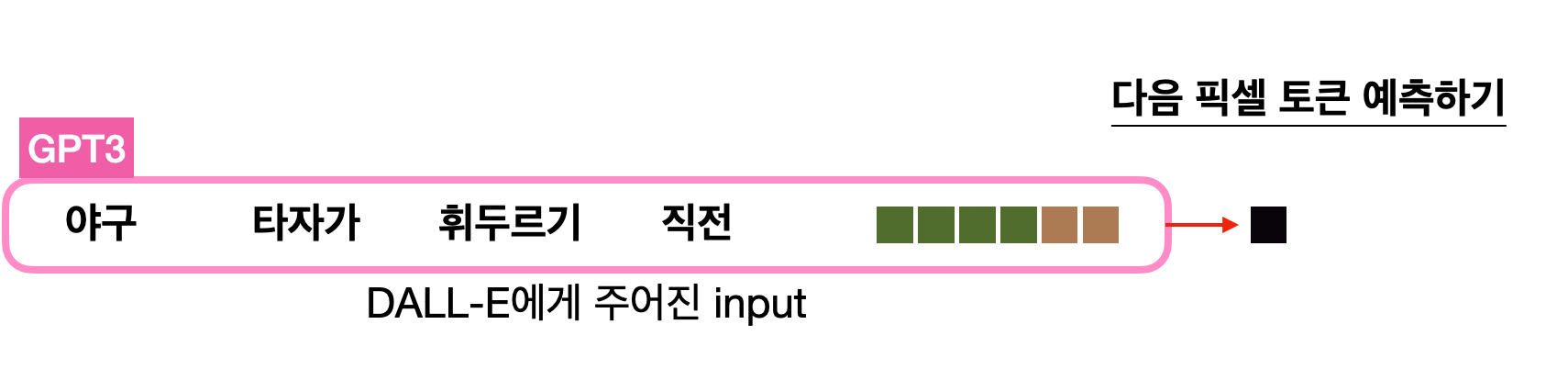
(참고 - https://jiho-ml.com/weekly-nlp-40/)
반면에 Text2Art는 VQGAN을 사용합니다. GAN은 생성자와 판별자가 서로 경쟁하면서 학습을 합니다. VQGAN-CLIP도 마찬가지입니다. VQGAN이 이미지를 만들면, CLIP이 그 이미지가 해당 텍스트와 일치하는지 검사를 합니다. 이 과정을 여러번 반복하면 점점 텍스트 설명과 유사한 이미지가 생성됩니다.

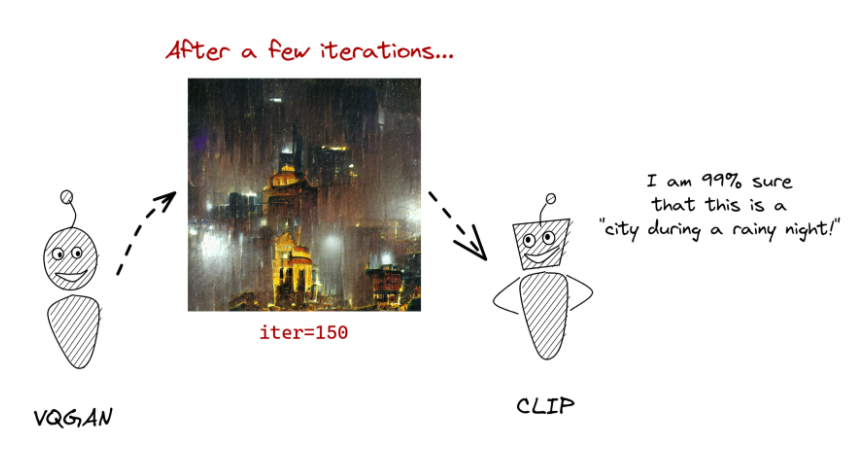
우리 뇌에서도 아마 같은 의미를 가진 다양한 형태의 개념들은 하나로 처리되지 않을까 생각됩니다. 예를 들어, '강아지'란 단어와 강아지의 이미지, 강아지가 내는 멍멍하는 소리는 서로 연결되어 있습니다. 우리는 강아지를 떠올리면 이런 개념들을 동시에 연상합니다. CLIP은 딥러닝도 같은 방식으로 동작할 수 있다는 것을 보여줬습니다. 앞으로 이를 활용한 재미있는 사례가 계속 나오지 않을까요.
< Text2Art >
< 개발과정 >
https://towardsdatascience.com/how-i-built-an-ai-text-to...
< Github >
https://github.com/mfrashad/text2art