

- AI Dev - 인공지능 개발자 모임
- 정보공유
- 자연어처리
글 수 72
http://gomguard.tistory.com/69
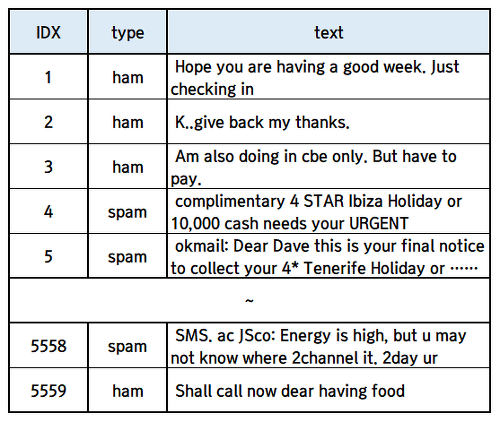
인공지능을 활용한 대표적인 방법으로 스팸 분류를 들 수 있습니다. 여기서 사용된 알고리즘은 바로 나이브 베이즈입니다. 베이즈 확률이란 어떤 정보가 주어졌을때 확률이 변하는 것을 의미합니다.
예를 들어, 트럼프 카드에서 스페이스 무늬가 나올 확률은 1/4입니다. 하지만 카드를 살짝 보니 검정색이었다는 정보를 얻었다면 1/2로 확률이 변합니다.
이렇게 조건이 주어졌을때 확률을 구하는 방법이 베이즈 정리입니다. 특히 이를 단순화한 나이브 베이즈를 많이 사용합니다.
P(A|B) = P(B|A)P(A)/P(B)
문서가 스팸인지를 알고 싶다면 P(스팸|문서)의 확률을 구해야 합니다. 이 확률은 구하기 어렵지만 P(문서|스팸)은 데이터셋을 통해서 얻을 수가 있습니다.
문서는 단어들의 집합이기 때문에 다음과 같이 변경할 수 있습니다. P(단어1|스팸)*P(단어2|스팸)*P(단어3|스팸)*... 각각의 확률은 스팸으로 분류된 전체 문서들의 단어의 개수에서 특정 단어의 개수를 구해 계산할 수 있습니다.