

- AI Dev - 인공지능 개발자 모임
- 정보공유
- 자연어처리
SKT 누구의 지식베이스를 설명한 자료입니다. 특히 인공지능 스피커에서 가장 많이 사용하는 것 중 하나가 지식검색입니다. 이를 위해서는 첫째, 웹에서 데이터를 크롤링하여 구조적으로 저장을 합니다. 위키 같은 경우 일정한 형식에 맞게 이미 정리되어 있어 정보를 추출하기가 편합니다. 그리고 지식그래프로 각 항목과 속성별로 연결합니다.
아이유->키 : 160
아이유->나이 : 20
아이유->소속사 : 뮤직레코드
뮤직레코드->CEO : 김철수
뮤직레코드->위치 : 강남구 신사동
"아이유 소속사의 위치가 어디야?"라고 물어보면 먼저 의도와 개체를 파악합니다. 의도는 '정보검색'이고 개체는 '아이유, 소속사, 위치'입니다. 단순히 개체단어의 순서별로 추론을 할 수도 있습니다. 하지만 보다 정확하게 판단하기 위해서는 구문분석으로 의존관계를 검사해야 합니다.
아이유->소속사=>뮤직레코드->위치=>강남구 신사동
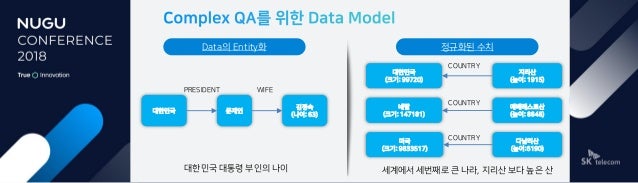
"지리산보다 높은 산은?", "서울에서 인구가 세번째로 도시는?" 같은 문장은 좀 더 복잡합니다. 우선 의도가 '정보검색'처럼 정형화된 방식이 아니라 '위치비교' 같은 별도의 의도로 처리해야 됩니다. 개체는 '지리산, 높은, 산' / '서울, 인구, 세번째, 도시'입니다. 그리고 수치를 비교하여 탐색을 합니다.
list = sort(mountain->height)
get_greater(list, 지리산->height)
문제는 "지구에서 달까지의 거리는", "소지섭과 공효진이 같이 나온 드라마는" 같이 처리 방법이 다른 문장들은 각각 개별 의도로 분류하고 직접 프로그래머가 코드를 작성해야 합니다.
사람이 일일히 카테고리나 속성을 지정하지 않고 자동으로 지식그래프를 생성하고, 추론 역시 인공지능이 알아서 해주는 알고리즘이 나올 수 있을까요. 그 전까지는 위와 같이 개발자가 모든 것을 미리 설계하여 구현을 해야될 듯 합니다.