

- AI Dev - 인공지능 개발자 모임
- 정보공유
- 자연어처리
글 수 72
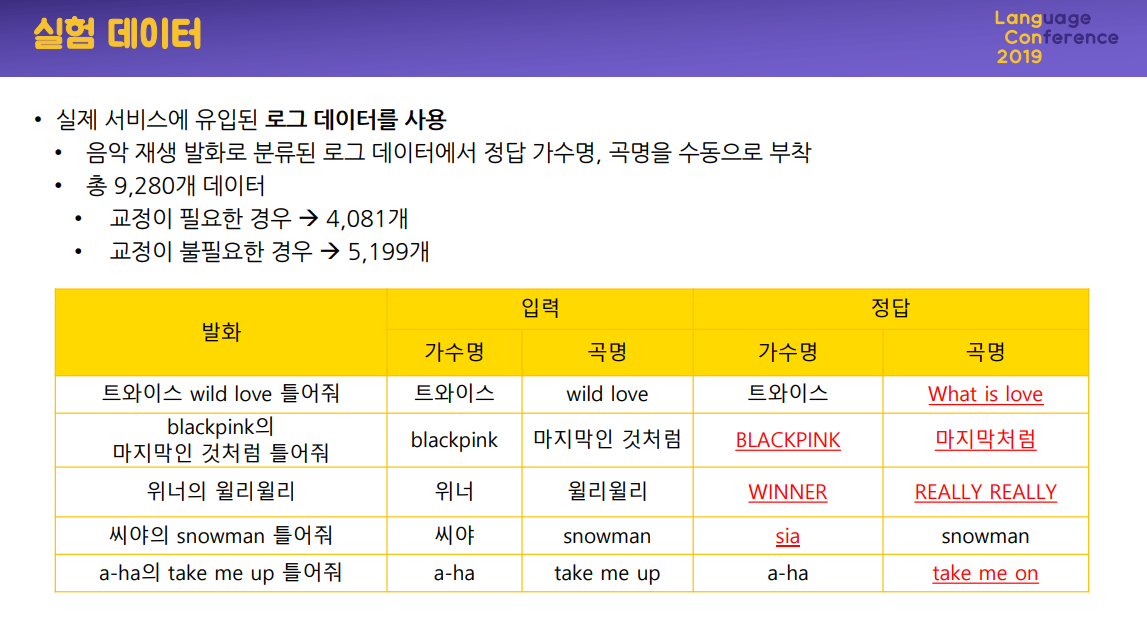
카카오미니에서 음성인식으로 변환한 텍스트의 오류를 어떻게 교정하는지 설명한 자료입니다. 예를 들어, '트와이스의 wild love 틀어줘'라고 인식했다면 '가수명->트와이스', '곡명->wild love'라고 엔티티를 추출합니다. 하지만 실제 곡명인 'what is love'로 수정해야 정확한 음악을 들려줄 수 있습니다.
이를 위해 먼저 전체, 가수명, 곡명에 따라 모든 데이터와 비교하여 총 16개의 유사도를 구합니다. 여기서 단순히 16개 유사도의 합이 가장 높은 곡을 선택하면 안됩니다. 각 유사도마다 가중치를 조절해야 하기 때문입니다.
바로 여기에서 학습이 사용됩니다. 16개의 유사도가 입력으로 들어가고 '교정/비교정'으로 출력이 나옵니다. 사람이 직접 라벨을 달은 데이터를 기반으로 랜덤 포레스트 모델로 학습을 했다고 합니다. 이진 출력이 확률로 나오기 때문에 아마 가장 높은 출력값이 나온 것을 정답으로 선택하지 않았을까 합니다.
< 엔티티 추출 >
트와이스 / wild love
< 오류 교정 >
트와이스 / what is love -> 0.8 (정답!)
트와이스 / I love you baby -> 0.6
아이유 / love attack -> 0.4