

- AI Dev - 인공지능 개발자 모임
- 정보공유
- 자연어처리
http://www.bloter.net/archives/264262
https://thinkwarelab.wordpress.com/2016
TF-IDF(Term Frequency-Inverse Document Frequency)는 문서(Document)내에서 단어(Term)의 중요도를 빈도(Frequency)를 사용해서 계산하는 방법입니다.
뉴스 기사에서 가장 핵심이 되는 단어가 무엇인지 찾는 방법을 생각해 보겠습니다. 우선 가장 먼저 떠오르는 것은 전체 문서에서 가장 많이 반복되는 단어를 구하는 것입니다. 예를 들어 인공지능에 대한 기사라면 당연히 인공지능이란 용어가 여러번 사용될 것입니다. 이것이 바로 TF입니다.
하지만 이것만 가지고는 정확한 결과를 얻기 힘듭니다. 컴퓨터나 회사, 개발 등 크게 중요하지 않지만 여러번 반복되는 단어가 있을 가능성이 크기 때문입니다. 그렇기 때문에 이런 단어들을 제외시킬 수 있는 새로운 방법이 필요합니다.
이 문서에 많이 반복되지만 다른 문서에도 동일하게 여러번 나오는 단어들은 크게 중요하지 않다고 판단할 수 있습니다. 그래서 각 단어가 문서 전체에 나오는 빈도를 구한 다음 이를 역으로 곱하면 그 단어의 중요도를 감소시킬 수 있습니다. 이것이 IDF입니다.
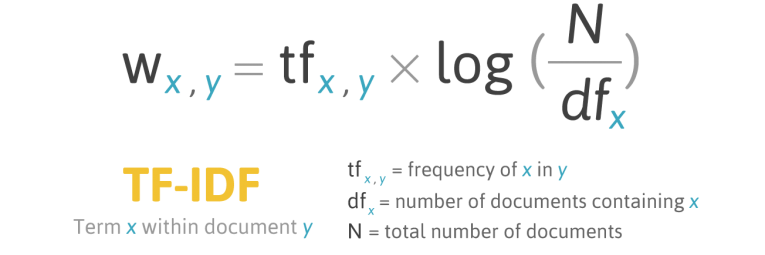
수식은 위와 같습니다. w는 문서 y에서 단어 x의 중요도입니다. 오른쪽의 IDF 부분을 로그로 계산한 것은 숫자가 너무 커지는 것을 방지하기 위해서 입니다. 로그 함수의 특성상 입력에 비해 출력이 서서히 증가하기 때문입니다.