

- AI Dev - 인공지능 개발자 모임
- 정보공유
- 강화학습
http://solarisailab.com/archives/486
강화학습의 한 방법인 DQN(Deep Q-Network)는 기존 Q-Learning에 신경망을 결합한 것입니다. Q-Learning은 상태집합에서 어떤 행동을 해야할지를 학습하는 알고리즘입니다.
현재 상태 s에서 행동 a를 했을때의 이득값 Q(s, a)을 알 수 있다면 모든 행동 a에 대해서 가장 높은 Q값을 갖는 행동을 수행하면 됩니다. Q(s, a)함수는 보통 테이블로 이루어져 있는데 (상태 x 행동) 배열이 바로 Q값을 나타냅니다. 예를 들어 위의 캐치게임의 Q테이블은 다음과 같이 정의할 수 있습니다.
과일 X좌표 * 과일 Y좌표 * 바구니 X좌표 * 바구니 행동(왼쪽, 대기, 오른쪽)
=> 10 * 10 * 10 * 3 = 3000
주어진 환경에서 반복적으로 동작을 하면서 아래와 같은 수식으로 Q값을 조정합니다.

r은 보상값(reward)이고 γ는 감소값(discount factor, 0~1)입니다. Q값은 보상값 r 더하기 다음에 할 수 있는 행동들의 Q값중 가장 높은 것에 감소값을 곱한값입니다.
이렇게 보상값이 점점 주변 상태로 조금씩 감소되면서 퍼져나갑니다. 그렇기 때문에 멀리 떨어진 상태에서도 목표를 향해 순차적으로 올바른 행동을 결정할 수 있습니다.
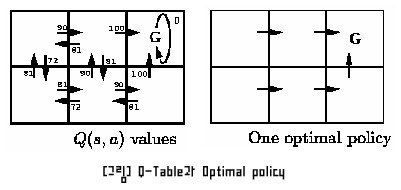
위의 Q테이블에서 화살표는 행동을 나타내는데 실제로는 이것도 배열로 표현됩니다. 여기서 목표 G에 도착하면 100의 보상값을 받습니다.
G의 왼쪽 상태에서 Q값은 0(보상값) + 0.9(감소값) * 100(행동중 가장 높은 Q값)으로 90입니다. G의 가장 왼쪽 상태에서 Q값은 0(보상값) + 0.9(감소값) * 90(행동중 가장 높은 Q값)으로 81입니다.
여러번 행동을 수행할수록 모든 상태에 대해서 Q테이블이 채워지게 됩니다. 그렇게 되면 오른쪽 그림처럼 각 상태마다 목표를 향한 최적의 행동을 결정할 수 있습니다.
캐치게임의 상태를 각 요소별이 아니라 화면의 픽셀정보만 사용해서 표현할 수도 있습니다.
픽셀당 상태 ^ (픽셀의 X좌표 * 픽셀의 Y좌표) * 바구니 행동 = 2 ^ (10 * 10) * 3
=> 3802951800684688204490109616128
보시다시피 상태의 개수가 엄청나기 때문에 배열로는 구현하기가 힘듭니다. 이처럼 상태집합이 클 경우에는 신경망을 사용할 수 있는데 그중에서도 딥러닝으로 Q테이블을 구하는 방법이 DQN입니다.
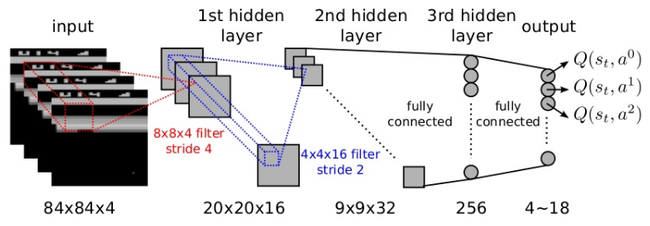
게임에서 픽셀정보를 입력으로 받아 딥러닝 CNN으로 학습을 합니다. 출력 결과는 행동의 개수만큼 나오는데 각 행동일때의 Q값을 나타냅니다.
캐치게임을 학습하는 코드는 아래와 같습니다. 원래 소스에서 getBatch()함수에 오류가 있는 것 같아 조금 수정하였습니다.
그리고 복잡한 게임이 아니라서 그런지 CNN 대신 히든레이어가 2개인 신경망이 사용되었습니다. 밑의 output_layer가 사실 hidden_layer2라고 보시면 됩니다.
-----------------------------------------------------------------
import tensorflow as tf
import numpy as np
import random
import math
import os
#----------------------------
# 파라미터 설정
#----------------------------
epsilon = 1 # 랜덤하게 행동할 확률
epsilonMinimumValue = 0.001 # epsilon의 최소값
nbActions = 3 # 행동의 개수 (왼쪽, 대기, 오른쪽)
epoch = 1001 # 게임 반복횟수
hiddenSize = 100 # 히든 레이어 뉴런 개수
maxMemory = 500 # 게임내용을 기억하는 최대 개수
batchSize = 50 # 학습시 데이터 묶음 개수
gridSize = 10 # 격자 크기
nbStates = gridSize * gridSize # 상태 개수
discount = 0.9 # 감소값
learningRate = 0.2 # 학습률
#----------------------------
# 모델 설정
#----------------------------
# 입력 레이어
X = tf.placeholder(tf.float32, [None, nbStates])
W1 = tf.Variable(tf.truncated_normal([nbStates, hiddenSize], stddev=1.0 / math.sqrt(float(nbStates))))
b1 = tf.Variable(tf.truncated_normal([hiddenSize], stddev=0.01))
input_layer = tf.nn.relu(tf.matmul(X, W1) + b1)
# 히든 레이어
W2 = tf.Variable(tf.truncated_normal([hiddenSize, hiddenSize],stddev=1.0 /
math.sqrt(float(hiddenSize))))
b2 = tf.Variable(tf.truncated_normal([hiddenSize], stddev=0.01))
hidden_layer = tf.nn.relu(tf.matmul(input_layer, W2) + b2)
#출력 레이어
W3 = tf.Variable(tf.truncated_normal([hiddenSize, nbActions],stddev=1.0 / math.sqrt(float(hiddenSize))))
b3 = tf.Variable(tf.truncated_normal([nbActions], stddev=0.01))
output_layer = tf.matmul(hidden_layer, W3) + b3
# 목표값 플레이스홀더
Y = tf.placeholder(tf.float32, [None, nbActions])
# 목표값과 출력값의 차이인 코스트
cost = tf.reduce_sum(tf.square(Y-output_layer)) / (2*batchSize)
# 경사하강법으로 코스트가 최소가 되는 값 찾음
optimizer = tf.train.GradientDescentOptimizer(learningRate).minimize(cost)
#----------------------------
# 랜덤값 구함
#----------------------------
def randf(s, e):
return (float(random.randrange(0, (e - s) * 9999)) / 10000) + s;
#----------------------------
# 환경 클래스
#----------------------------
class CatchEnvironment():
# 초기화
def __init__(self, gridSize):
self.gridSize = gridSize
self.nbStates = self.gridSize * self.gridSize
self.state = np.empty(3, dtype = np.uint8)
# 화면정보 리턴
def observe(self):
canvas = self.drawState()
canvas = np.reshape(canvas, (-1,self.nbStates))
return canvas
#블럭과 바를 표시하여 화면정보 리턴
def drawState(self):
canvas = np.zeros((self.gridSize, self.gridSize))
# 과일 표시
canvas[self.state[0]-1, self.state[1]-1] = 1
# 바구니 표시
canvas[self.gridSize-1, self.state[2] -1 - 1] = 1
canvas[self.gridSize-1, self.state[2] -1] = 1
canvas[self.gridSize-1, self.state[2] -1 + 1] = 1
return canvas
# 과일과 바구니 위치 초기화
def reset(self):
initialFruitColumn = random.randrange(1, self.gridSize + 1)
initialBucketPosition = random.randrange(2, self.gridSize + 1 - 1)
self.state = np.array([1, initialFruitColumn, initialBucketPosition])
return self.getState()
# 상태 리턴
def getState(self):
stateInfo = self.state
fruit_row = stateInfo[0]
fruit_col = stateInfo[1]
basket = stateInfo[2]
return fruit_row, fruit_col, basket
# 보상값 리턴
def getReward(self):
fruitRow, fruitColumn, basket = self.getState()
if (fruitRow == self.gridSize - 1): # If the fruit has reached the bottom.
if (abs(fruitColumn - basket) <= 1): # Check if the basket caught the fruit.
return 1
else:
return -1
else:
return 0
# 게임오버 검사
def isGameOver(self):
if (self.state[0] == self.gridSize - 1):
return True
else:
return False
# 상태 업데이트
def updateState(self, action):
if (action == 1):
action = -1 # 왼쪽 이동
elif (action == 2):
action = 0 # 대기
else:
action = 1 # 오른쪽 이동
fruitRow, fruitColumn, basket = self.getState()
newBasket = min(max(2, basket + action), self.gridSize - 1) # 바구니 위치 변경
fruitRow = fruitRow + 1 # 과일을 아래로 이동
self.state = np.array([fruitRow, fruitColumn, newBasket])
# 행동 수행 (1->왼쪽, 2->대기, 3->오른쪽)
def act(self, action):
self.updateState(action)
reward = self.getReward()
gameOver = self.isGameOver()
return self.observe(), reward, gameOver, self.getState()
#----------------------------
# 메모리 클래스
# 게임내용을 저장하고 나중에 배치로 묶어 학습에 사용
#----------------------------
class ReplayMemory:
# 초기화
def __init__(self, gridSize, maxMemory, discount):
self.maxMemory = maxMemory
self.gridSize = gridSize
self.nbStates = self.gridSize * self.gridSize
self.discount = discount
canvas = np.zeros((self.gridSize, self.gridSize))
canvas = np.reshape(canvas, (-1,self.nbStates))
self.inputState = np.empty((self.maxMemory, 100), dtype = np.float32)
self.actions = np.zeros(self.maxMemory, dtype = np.uint8)
self.nextState = np.empty((self.maxMemory, 100), dtype = np.float32)
self.gameOver = np.empty(self.maxMemory, dtype = np.bool)
self.rewards = np.empty(self.maxMemory, dtype = np.int8)
self.count = 0
self.current = 0
# 게임내용 추가
def remember(self, currentState, action, reward, nextState, gameOver):
self.actions[self.current] = action
self.rewards[self.current] = reward
self.inputState[self.current, ...] = currentState
self.nextState[self.current, ...] = nextState
self.gameOver[self.current] = gameOver
self.count = max(self.count, self.current + 1)
self.current = (self.current + 1) % self.maxMemory
# 게임내용을 배치로 묶어서 리턴
def getBatch(self, model, batchSize, nbActions, nbStates, sess, X):
memoryLength = self.count
chosenBatchSize = min(batchSize, memoryLength)
inputs = np.zeros((chosenBatchSize, nbStates))
targets = np.zeros((chosenBatchSize, nbActions))
for i in xrange(chosenBatchSize):
# 메모리에서 랜덤하게 선택
randomIndex = random.randrange(0, memoryLength)
current_inputState = np.reshape(self.inputState[randomIndex], (1, 100))
target = sess.run(model, feed_dict={X: current_inputState})
current_nextState = np.reshape(self.nextState[randomIndex], (1, 100))
current_outputs = sess.run(model, feed_dict={X: current_nextState})
# 다음 상태의 최대 Q값
nextStateMaxQ = np.amax(current_outputs)
if (self.gameOver[randomIndex] == True):
# 게임오버일때 Q값은 보상값으로 설정
target[0, [self.actions[randomIndex]-1]] = self.rewards[randomIndex]
else:
# Q값을 계산
# reward + discount(gamma) * max_a' Q(s',a')
target[0, [self.actions[randomIndex]-1]] = self.rewards[randomIndex] +
self.discount * nextStateMaxQ
inputs[i] = current_inputState
targets[i] = target
return inputs, targets
#----------------------------
# 메인 함수
#----------------------------
def main(_):
print("Training new model")
# 환경 정의
env = CatchEnvironment(gridSize)
# 메모리 정의
memory = ReplayMemory(gridSize, maxMemory, discount)
# 세이버 설정
saver = tf.train.Saver()
winCount = 0
with tf.Session() as sess:
tf.initialize_all_variables().run()
for i in xrange(epoch):
err = 0
env.reset()
isGameOver = False
currentState = env.observe()
while (isGameOver != True):
action = -9999
# 랜덤으로 행동을 할지 Q값에 따라 행동할지 결정
global epsilon
if (randf(0, 1) <= epsilon):
action = random.randrange(1, nbActions+1)
else:
q = sess.run(output_layer, feed_dict={X: currentState})
index = q.argmax()
action = index + 1
# 랜덤으로 행동할 확률 감소
if (epsilon > epsilonMinimumValue):
epsilon = epsilon * 0.999
# 행동 수행
nextState, reward, gameOver, stateInfo = env.act(action)
# 승리 횟수 설정
if (reward == 1):
winCount = winCount + 1
# 메모리에 저장
memory.remember(currentState, action, reward, nextState, gameOver)
# 다음 상태 설정
currentState = nextState
isGameOver = gameOver
# 입력과 출력 데이터 배치를 구함
inputs, targets = memory.getBatch(output_layer, batchSize, nbActions, nbStates, sess, X)
# 학습 수행
_, loss = sess.run([optimizer, cost], feed_dict={X: inputs, Y: targets})
err = err + loss
print("Epoch " + str(i) + ": err = " + str(err) + ": Win count = " + str(winCount) +
" Win ratio = " + str(float(winCount)/float(i+1)*100))
# 모델 세션 저장
save_path = saver.save(sess, os.getcwd()+"/model.ckpt")
print("Model saved in file: %s" % save_path)
#----------------------------
# 메인 함수 실행
#----------------------------
f __name__ == '__main__':
tf.app.run()
-----------------------------------------------------------------
< 인공지능 개발자 모임 >
- 페이스북 그룹에 가입하시면 인공지능에 대한 최신 정보를 쉽게 받으실 수 있습니다.
- https://www.facebook.com/groups/AIDevKr/