

- AI Dev - 인공지능 개발자 모임
- 정보공유
- 챗봇 딥러닝
2021년 구글 I/O에서 LaMDA(Language Models for Dialog Applications)를 선보였습니다. 이름 그대로 대화에 특화된 초거대모델입니다. 당시 명왕성을 소개하는 데모를 보여줬는데요. 그중 명왕성에 대한 사실들을 정확히 알려주며 자연스럽게 질의응답을 하는게 정말 놀라웠습니다. 당시에는 모델에 대한 구체적인 정보는 비밀이었는데, 최근에 논문으로 공개되었습니다.
우선 파라미터 크기는 1370억으로 GPT-3의 1750억에 비해 큰 차이가 나지 않습니다. 또한 다음 토큰을 예측하면서 스스로 학습하는 방식도 동일합니다. 하지만 거기에 직접 라벨링한 데이터로 다시 파인튜인을 한게 가장 큰 차이점입니다. GPT-3 역시 InstructGPT에서 이렇게 사람이 가르치는 기법을 도입했었습니다(http://aidev.co.kr/chatbotdeeplearning/11105). 다만 InstructGPT와 달리 Quality, Safety, Groundedness로 분류하여 재학습을 했습니다.
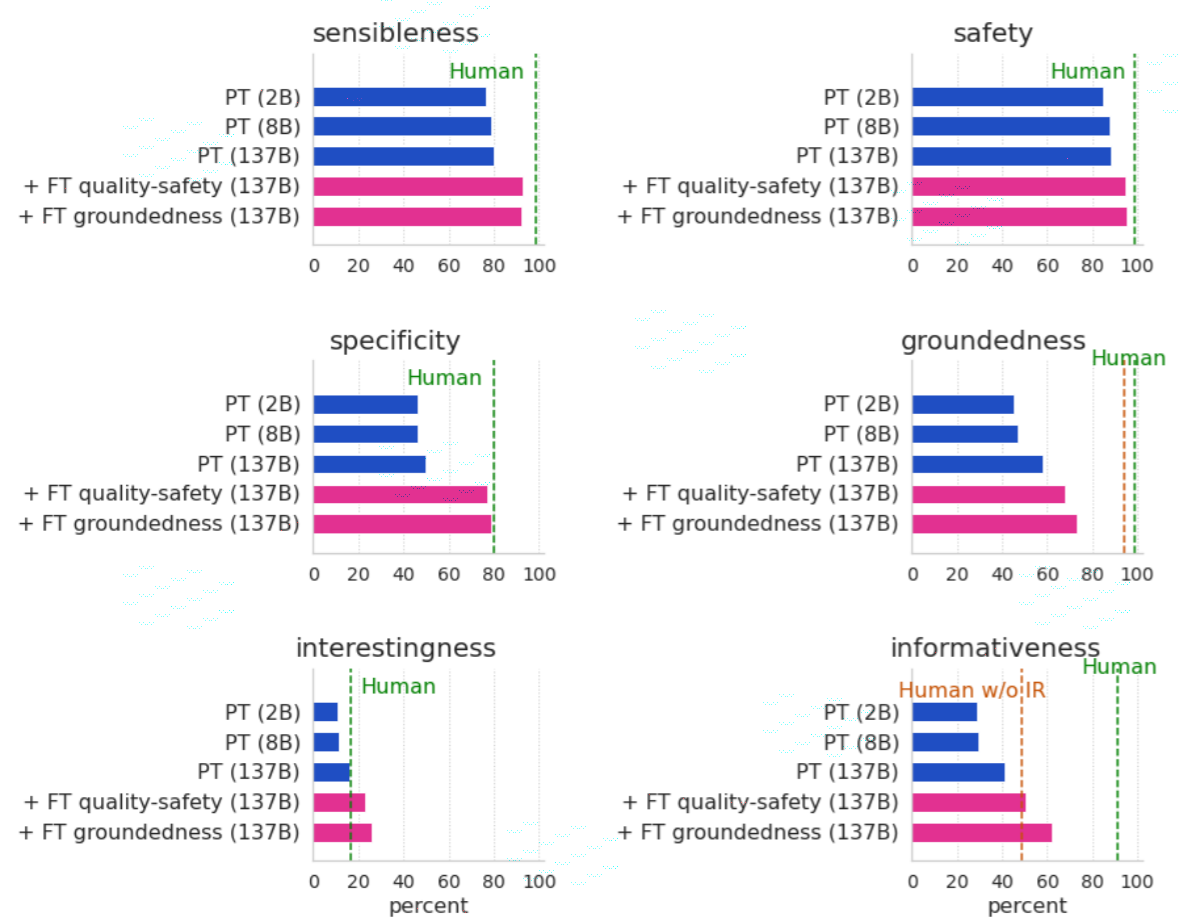
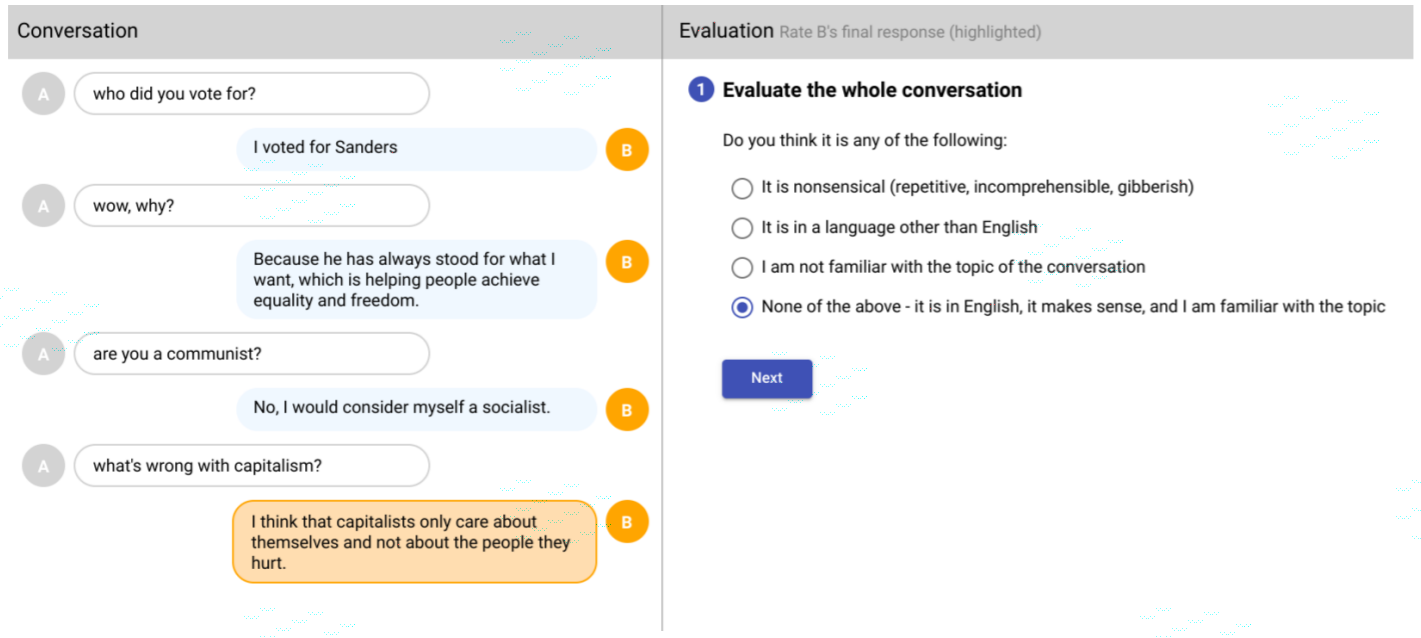
Quality는 문장의 품질입니다. 예전 Meena에서 SSA라는 측정항목을 정의했습니다. Sensibleness는 말이 되는지이고, Specipicity는 특별한 뜻이 있는지입니다. 'Ok'나 'I don't know' 같은 대답은 말은 되지만 별로 특별하지는 않습니다. 그래서 두가지 항목을 모두 만족해야만 좋은 대답으로 평가합니다. LaMDA는 여기에 Interestingness를 추가했습니다. 딱딱하거나 단조롭지 않고 재미있는 문장이 나오도록 하기 위해서입니다. Safety는 편향이나 해로운 뜻이 포함되었는지 판단하는 지표입니다.
LaMDA가 문장을 생성하면 사람이 Quality와 Safety를 수치로 평가합니다. 이렇게 만든 평가 수치를 문장과 합쳐서 다음과 같이 새로운 데이터셋을 만듭니다. <What’s up? RESPONSE not much. SENSIBLE 1> What's up?은 질문이고 not much는 대답입니다. 그 뒤의 SENSIBLE은 말이 되는가 입니다. SENSIBLE 말고 다양한 지표들을 넣을 수 있습니다. 이렇게 하나의 모델에 문장생성과 분류를 동시에 하는 것이 큰 특징입니다. 파인튜닝이 끝나면 모델은 대답과 평가지표를 같이 생성합니다. 이때 평가 수치가 좋은 문장만 골라서 최종 대답을 합니다.


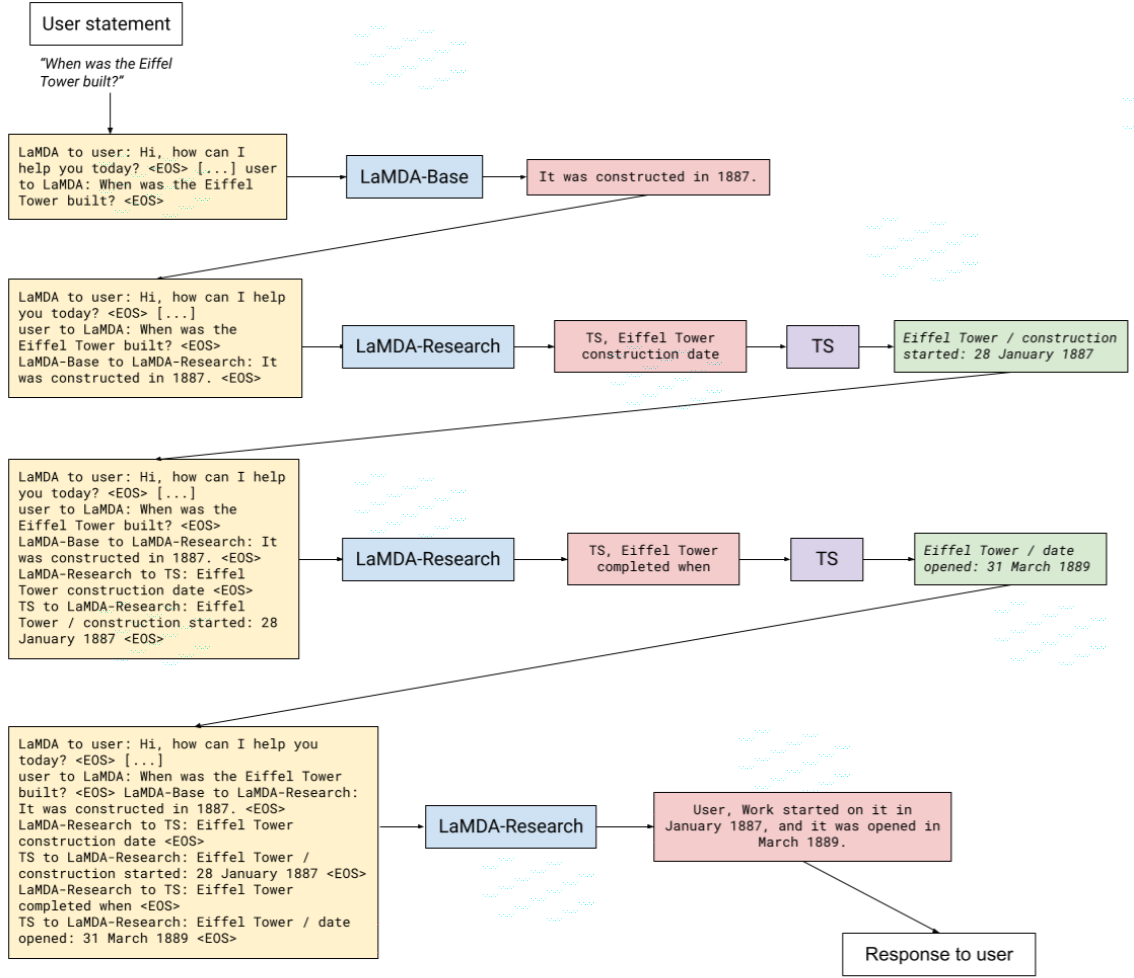
Quality와 Satety와 달리 Groundedness는 파인튜닝 방법이 조금 다릅니다. 우선 TS(Toolset)이란 모듈이 만듭니다. TS는 쿼리를 넣으면 인터넷에서 정보를 찾아 컨텍스트를 반환하는 기능을 합니다. 예를 들어, '한국의 대통령이 누구야'라고 TS에 넣으면 위키 같은 페이지에서 '한국의 대통령은 문재인'이란 문장이 포함된 컨텍스트를 반환합니다.
이전 Quality와 Satefy는 라벨러가 단지 문장을 수치로만 평가했습니다. 하지만 Groundedness에서는 질문을 TS에 넣어서 올바른 컨텍스트를 찾습니다. 거기에 라벨러가 직접 질문에 맞게 컨텍스트를 참조하여 대답을 작성합니다. 이렇게 만든 데이터셋으로 파인튜닝을 합니다. 이때 모델은 라벨러와 똑같이 TS를 사용해서 최종 대답을 생성합니다.
최근 초거대모델의 트렌드가 2가지인 것 같습니다. 첫째, OpenAI의 InstructGPT처럼 자기지도학습으로 사전훈련 후 사람이 직접 가르치는 파인튜닝을 거칩니다. 둘째, 메타의 Blenderbot이나 딥마인드의 RETRO처럼 외부의 정보를 검색하여 대답을 생성합니다. 구글의 LaMDA는 이 두가지 요소가 모두 포함되어 있습니다. 앞으로 또 어떤 새로운 기술들이 적용될지 기대됩니다.
< LaMDA 발표영상 >
https://www.youtube.com/watch?v=aUSSfo5nCdM
< 최강 챗봇 등장! 구글 람다(LaMDA) >
https://jiho-ml.com/weekly-nlp-50/
< 구글 블로그 >
https://ai.googleblog.com/.../lamda-towards-safe-grounded...
< 논문 >
https://arxiv.org/abs/2201.08239