

- AI Dev - 인공지능 개발자 모임
- 정보공유
- 자연어처리
글 수 72
https://bab2min.tistory.com/552
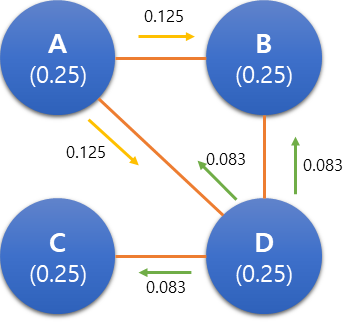
구글 검색의 핵심 알고리즘은 PageRank입니다. 링크를 많이 받은 페이지의 점수를 높게 부여하는게 기본 원리입니다. 이와 비슷한 방법을 텍스트에 적용한 TextRank를 설명하고 있습니다.
좌우로 일정 영역에 같이 위치하고 있으면 링크가 연결되어 있다고 판단합니다. 이렇게 단어 또는 문장 단위로 그래프를 연결하고 중요도를 계산합니다. 키워드나 문장요약에 활용할 수 있습니다.
저도 해봤는데 성능이 그렇게 좋지는 않습니다. 특히 '난, 같이, 것' 등의 기본 단어들이 걸려지지 않는게 가장 큰 문제입니다. TF-IDF를 함께 사용하여 다른 문서에서도 빈번하게 쓰이는 단어를 제거해주는 것이 좋을 듯 합니다.