

- AI Dev - 인공지능 개발자 모임
- 정보공유
- 자연어처리
아마존에서 발표한 새로운 질의응답 모델입니다. 챗봇이나 인공지능 스피커의 대표적인 기능이 바로 질문에 대한 대답입니다. 보통 "현재 미국의 대통령 이름은?" 같은 단순한 문장으로 물어봅니다. 하지만 "올해 개봉한 한국 영화 중 칸에서 상을 받은 것은?" 처럼 여러가지 사실들을 복합적으로 고려하는 경우도 많습니다. 이를 해결하는 전통적인 방법은 크게 두 가지 입니다.
첫째, 검색엔진과 비슷하게 문장의 유사도를 통해 해답을 찾습니다. 웹에서 수집한 문서에서 '올해/개봉/한국영화/칸/상' 같은 키워드를 중심으로 그 주변에 있는 엔티티들을 추출합니다. 그리고 가장 점수가 높은 단어(기생충)을 정답으로 선택합니다. 둘째, 지식그래프를 사용합니다. 미리 정보들의 관계를 추상화한 방대한 지식그래프를 생성합니다. 그리고 추론을 통해 질문에 대한 답을 도출합니다.
지식그래프는 시간이 갈수록 정확도가 떨어질 수 있다는 문제가 있습니다. 계속 새로운 정보로 갱신하기가 어렵기 때문입니다. 또한 최근에 일어난 일들에 대해서는 처리하기가 어렵습니다. 이를 해결하기 위해 검색과 지식그래프를 통합한 새로운 알고리즘을 제시하였습니다. 질문이 들어오면 웹검색을 하고, 그 결과를 바로 지식그래프로 변환합니다. 사진을 보면 "오스카상을 받고 골든글로브를 놓친 놀란의 영화는?"에 대한 추론 과정이 나와있습니다.
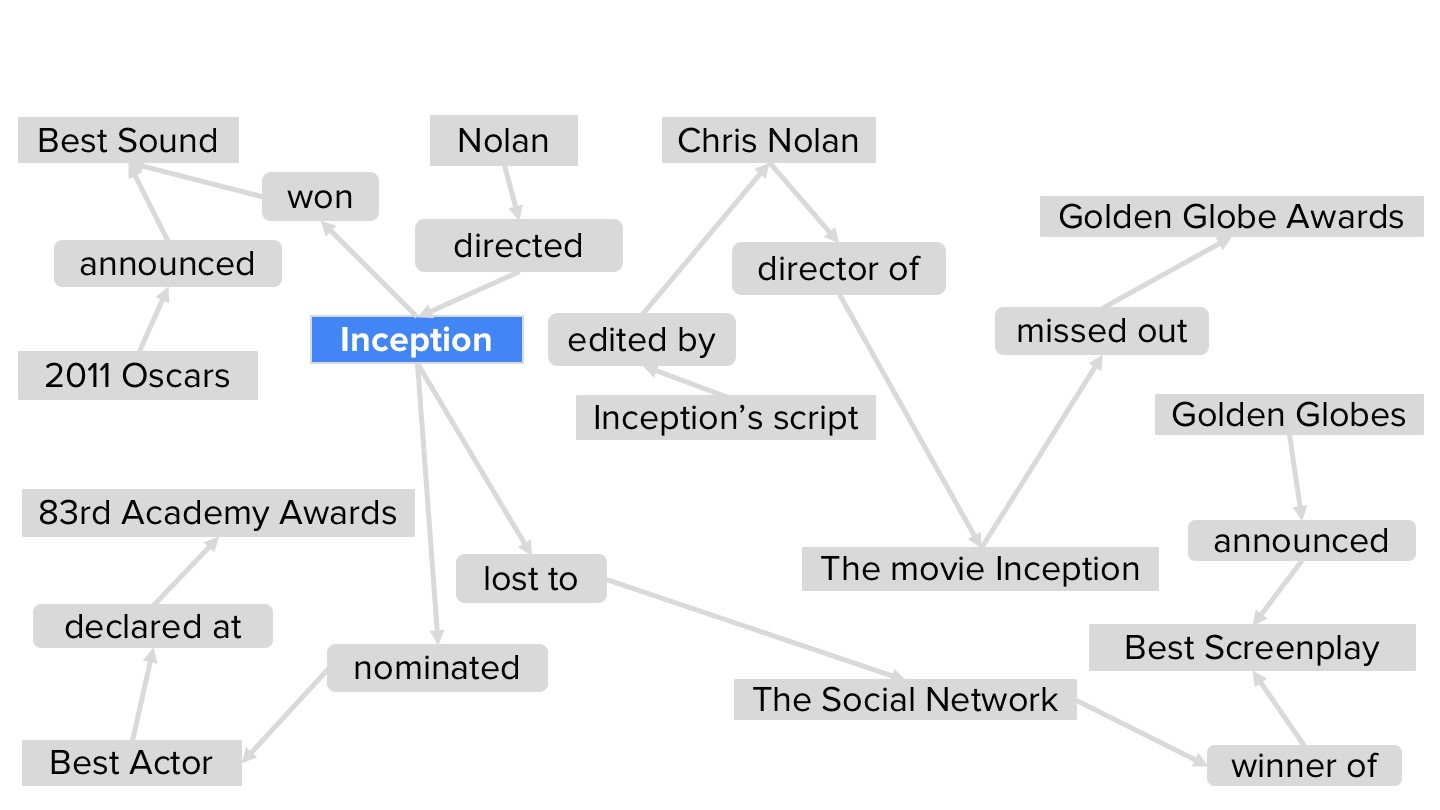
먼저 웹페이지를 검색하여 (주어, 술어, 목적어)로 된 정보를 추출하고 지식그래프로 연결합니다.
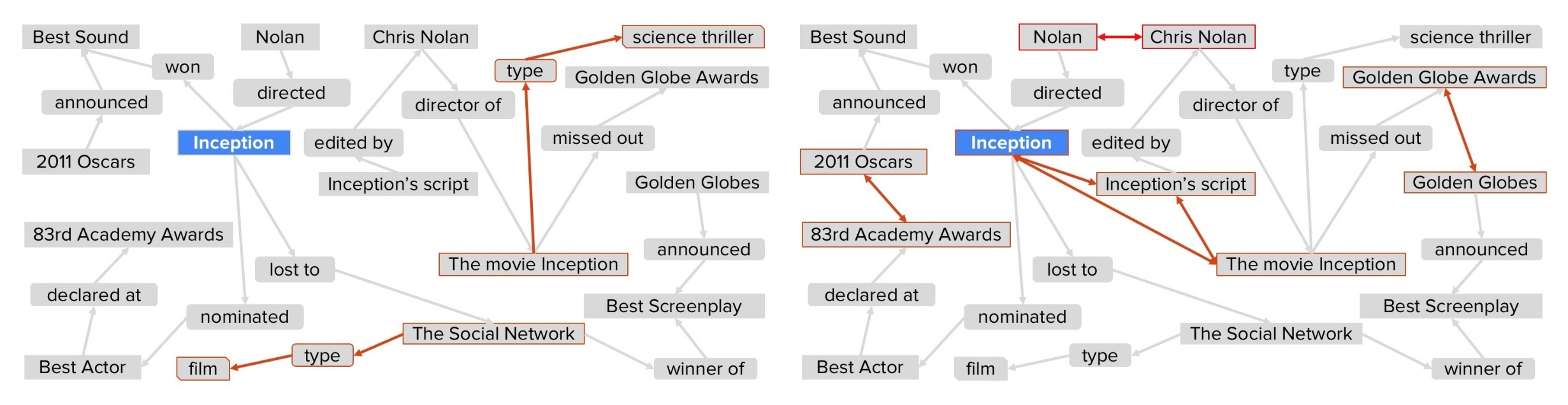
그다음 이미 구축한 데이터를 사용하여 지식그래프를 보강합니다.
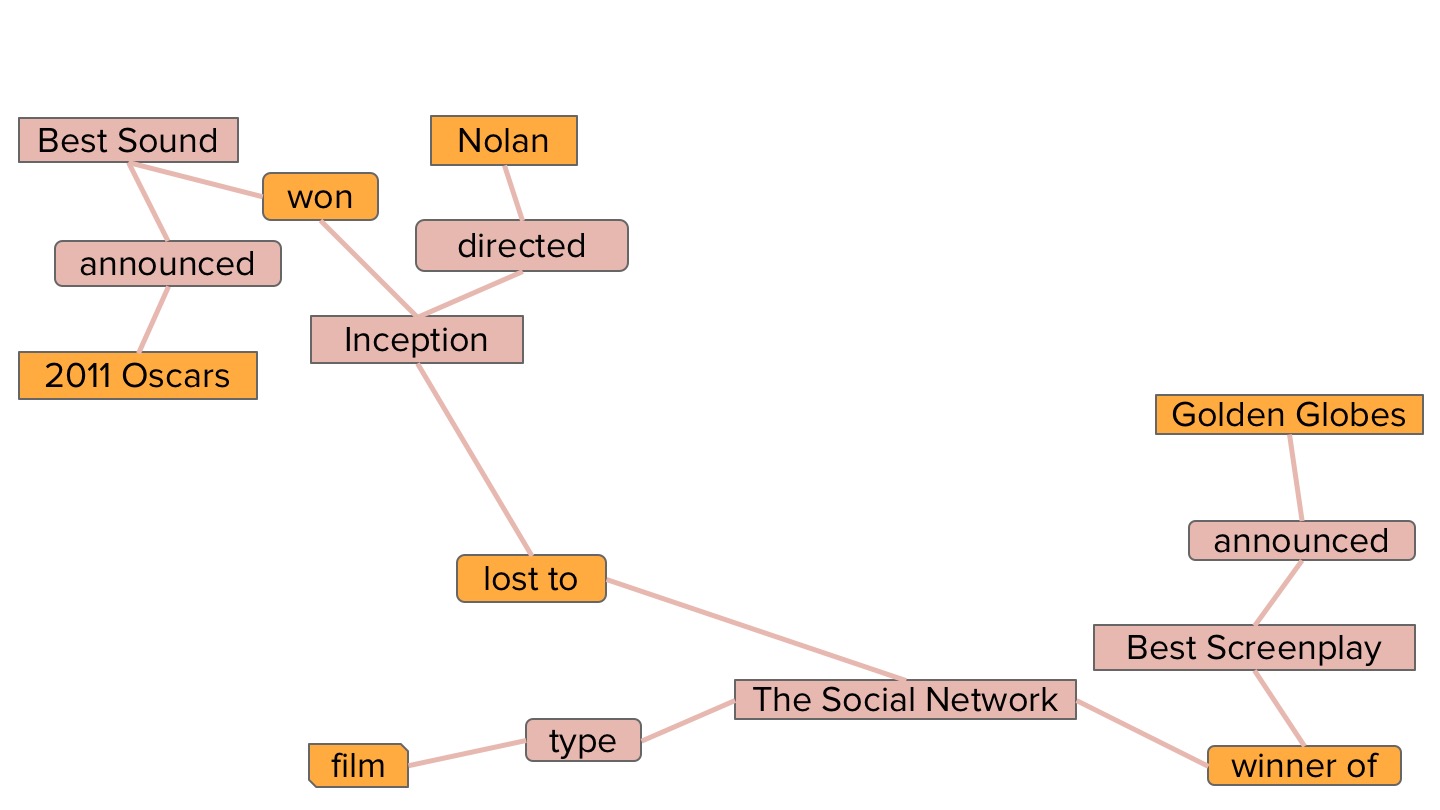
토대(cornerstones)가 되는 엔티티들을 선택하고 점수가 높은 항목만 남김니다.
마지막으로 최종 정답을 선택합니다.
논문 결과를 보면 딥러닝 기법을 사용한 페이스북의 DrQA보다 훨씬 성능이 높습니다. 하지만 아마 몇 년후에는 질의응답도 딥러닝 방식으로 패러다임이 변하지 않을까 생각됩니다. 물론 웹의 방대한 지식을 딥러닝 모델에 저장하기는 불가능합니다. 먼저 검색엔진으로 몇 개 페이지만 고릅니다. 그리고 이를 컨텍스트로 하고 질문 문장과 같이 모델에 입력합니다. 딥러닝은 컨텍스트에서 질문의 대답을 찾는 거라고 보시면 됩니다. 가상비서의 가장 큰 역할이 질의응답인 만큼, 이 분야가 앞으로 급속도로 발전할 것 같습니다.
< 블로그 >
< 논문 >
-> Answering Complex Questions by Joining Multi-Document Evidence with Quasi Knowledge Graphs
-> https://alexapapers.s3.us-east-2.amazonaws.com/Joint+QA+system.pdf