

- AI Dev - 인공지능 개발자 모임
- 정보공유
- 머신러닝
글 수 34
https://brunch.co.kr/@chris-song/54
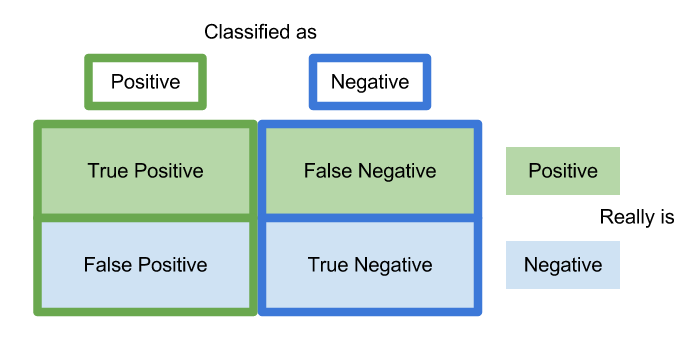
머신러닝의 평가 기준에 대해서 잘 설명한 글입니다. 모델을 평가할 때 보통 정확도(accuracy)를 많이 사용합니다. 데이터의 전체 개수에서 맞게 판단한 개수의 비율입니다. 예를 들어, 100개 중 99개가 일치한다면 99%의 정확도입니다.
하지만 데이터의 클래스가 한쪽으로 편중되어 있을 경우 문제가 발생합니다. 100개 중 1개가 암이고 99개가 정상인 데이터가 있습니다. 다음과 같은 2개의 모델이 있다고 생각해보겠습니다.
< 모델A >
- 99개 정상 데이터 : 모두 맞힘
- 1개 암 데이터 : 틀림
- 정확도 : 99%
< 모델B >
- 99개 정상 데이터 : 98개 맞힘/1개 틀림
- 1개 암 데이터 : 맞힘
- 정확도 : 99%
같은 99%의 정확도이지만 암 데이터를 맞힌 모델B가 더 뛰어나다고 볼 수 있습니다. 이렇게 정확도로 판단하기 어려운 상황이 많이 발생합니다. 그럴 경우 정밀도(precision)나 검출율(recall) 같은 다른 평가 방법을 적용하는 것이 좋습니다.