

- AI Dev - 인공지능 개발자 모임
- 정보공유
- 챗봇 딥러닝
챗봇을 개발할 때 가장 중요한 것 중 하나는 입력된 문장의 의도를 정확하게 판단하는 것입니다. 하지만 미리 정의된 문장에서 조금만 변형이 되면 인식을 못하는 경우가 대부분입니다. 왜 이런 문제가 발생하고 그 해결 방안에는 어떤 것들이 있는지 알아보겠습니다.
문장의 의도 파악
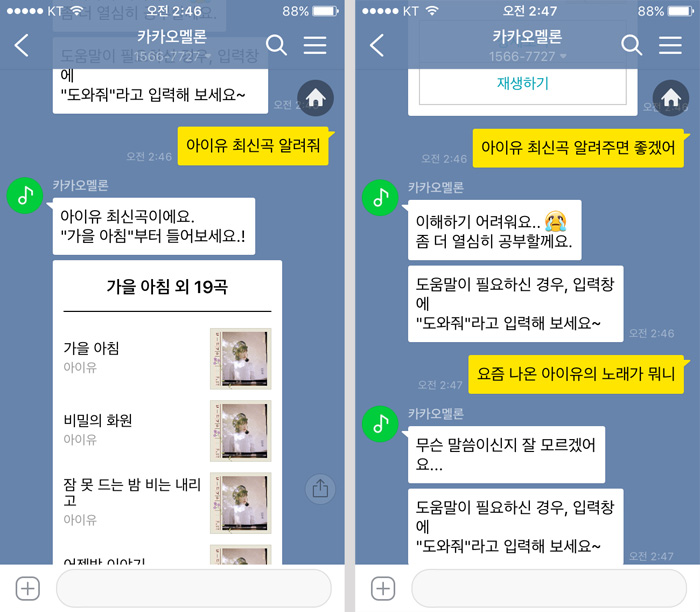
비슷한 문장을 판단할 때 고려해야 할 첫번째 사항은 동사의 변화입니다. 위의 사진처럼 '알려줘'는 인식하지만 '알려주면 좋겠어'처럼 어미가 변하면 이해하지 못합니다.
두번째는 동의어의 유무입니다. '아이유 최신곡 뭐야' 같이 유사한 뜻을 가진 단어를 사용했을 때도 같은 의미로 인식할 수 있어야 합니다.
세번째는 문장의 구조가 달라졌을 경우입니다. '요즘 나온 아이유의 노래가 뭐니'의 경우 단순히 단어만 바뀐 것이 아니라 형태 자체가 변경되었습니다.
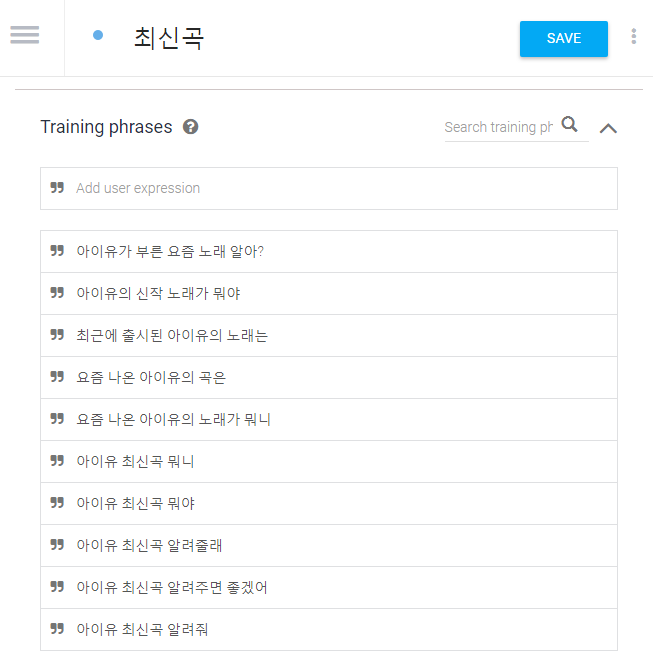
이를 해결하기 위해서는 의도에 다양한 문장을 미리 입력하는 수밖에 없습니다. 의도가 몇 개 되지 않는다면 가능하겠지만 종류가 늘어날수록 사람이 해야할 작업량이 급격히 증가합니다. 예를 들어, 100개의 의도가 있고 각각 30개의 문장을 설정한다면 무려 3000개의 문장을 일일이 입력해야 합니다.
만약 하나의 문장만 입력해도 사용자가 물어보는 비슷한 질문들의 의도를 자동으로 파악할 수 있다면 어떨까요. 챗봇 빌더에서 이런 기능을 제공한다면 챗봇을 구현하는데 큰 도움이 될 것입니다.
규칙기반으로 유사도 측정
비슷한 문장을 판단하는 첫 번째 방법은 형태소분석을 통해 동사의 어간만 비교를 하는 것입니다. 다음과 같이 '알리'만 일치하면 같은 의미로 처리할 수 있습니다.
알려줘 : 알리+어+주+어
알려줄래 : 알리+어+주+ㄹ래
알려주면 좋겠어 : 알리+어+주+면+좋+겠+어
하지만 어미에 의해 뜻이 바뀌는 경우 문제가 발생할 수 있다는 단점이 있습니다.
알려주지마 : 알리+어+주+지+마
알려주기 싫어 : 알리+어+주+기+싫+어
그리고 동의어 사전을 만들어서 유사한 의미를 갖는 단어인지 검사를 합니다. 하지만 이런 동의어 사전을 구하기가 쉽지 않고, 챗봇에서는 보다 넓은 범위로 판단을 하기 때문에 별도의 작업이 필요할 것 같습니다.
[동의어] : 알리, 뭐, 말, ...
알려줘 : 알리+어+주+어
뭐야 : 뭐+야
말해줘 : 말+하+아+주+어
또 하나의 단점은 이런 방법으로는 문장의 구조가 완전히 다른 경우 올바르게 판별하기 어렵다는 것입니다. 역시 규칙기반 보다는 딥러닝으로 스스로 학습하는 방식이 더 적합하지 않을까 생각합니다.
RNN으로 유사도 측정
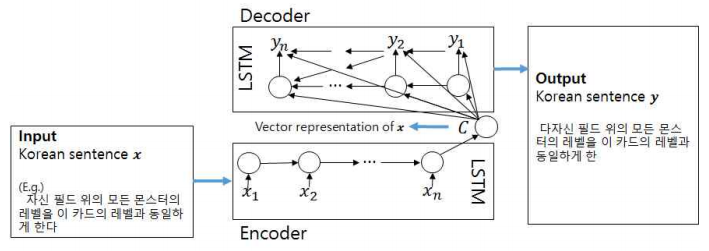
딥러닝의 RNN을 사용하여 문장의 유사도를 측정할 수 있습니다. Seq2Seq는 2개의 RNN을 연결하여 텍스트를 생성하는 모델입니다. 입력과 출력이 같은 문장이 되도록 학습을 시키면 인코더의 출력인 벡터는 문장을 압축한 정보를 나타냅니다. 이 값의 코사인 유사도를 측정하여 두 문장이 얼마나 비슷한지 판별합니다.
하지만 '아이유 최신곡 알려줘'와 '요즘 나온 아이유의 노래가 뭐니' 처럼 문장의 구조가 다른 경우에는 성능이 좋지 않다는 문제가 있습니다. 그렇기 때문에 실제로 챗봇에 적용하기는 어려울 것 같습니다.
< 참고 자료 >
Siamese Network로 유사도 측정
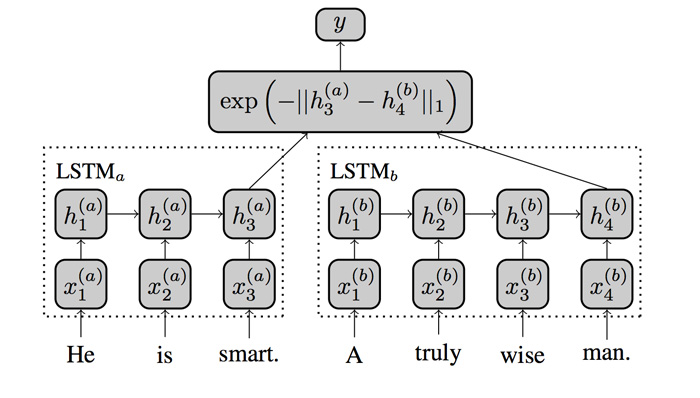
Siamese Network는 샴쌍둥이처럼 두 개의 동일한 RNN을 사용합니다. 동시에 두 문장을 입력으로 받아 '일치/불일치'를 결정하도록 학습합니다. 그렇기 때문에 서로 다른 구조의 문장도 유사하다는 것을 정확히 판단할 수 있습니다.
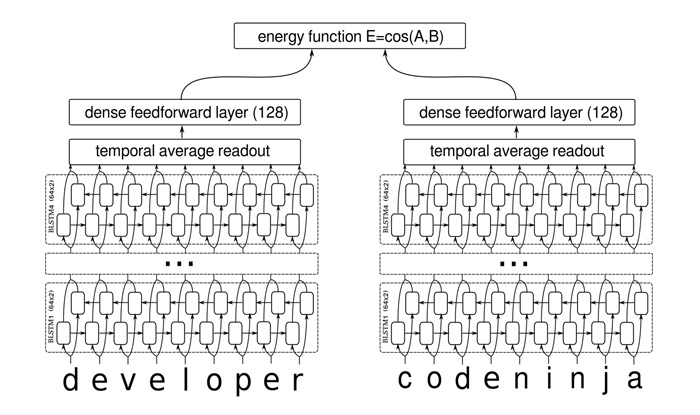
단어 기반이 아니라 위와 같이 캐릭터 문자 기반으로도 네트워크를 구성할 수 있습니다.
< 참고 자료 >
- https://github.com/dhwajraj/deep-siamese-text-similarity
- Siamese Recurrent Architectures for Learning Sentence Similarity
- Learning Text Similarity with Siamese Recurrent Networks
정리
제가 사용해본 챗봇 빌더 중에서는 이런 기능을 지원하는 곳이 아직 없었습니다. 하지만 앞으로 유사도를 자동으로 처리해주는 플랫폼이 곧 나오지 않을까 생각됩니다. 만약 그게 가능하다면 다른 제품과의 경쟁에서 상당히 유리해 질 수 있습니다.
하지만 문제는 딥러닝으로 학습을 하기 위한 데이터가 필요하다는 것입니다. 두 문장이 일치하는지 레이블이 되어 있는 데이터를 사람이 직접 작성을 해야합니다. 페이페이 리가 방대한 사진 정보를 담고 있는 ImageNet을 만든 것처럼 문장에 대한 정보를 모아둔 TextNet이 필요할지도 모르겠습니다.
< 챗봇 개발자 모임 >
- 페이스북 그룹에 가입하시면 챗봇에 대한 최신 정보를 쉽게 받으실 수 있습니다.