

올해 1월에 OpenAI에서 주목할 만한 딥러닝 모델을 2가지 공개했습니다. 하나는 자연어로 이미지를 생성하는 DALL-E고, 다른 하나는 바로 CLIP(Contrastive Language–Image Pre-training)입니다. DALL-E는 많은 분들이 이미 뉴스기사를 통해 접하셨을 텐데요. 그에 반해 CLIP에 대한 관심은 조금 덜한 편입니다. 하지만 이 모델 역시 앞으로 딥러닝의 방향을 바꿀 만한 파괴력을 지니고 있다고 생각합니다.
딥러닝의 가장 대표적인 분야는 역시 이미지 인식입니다. 그 계기가 된 것은 2009년 공개된 ImageNet 데이터셋입니다. 사진과 정답라벨로 짝지어진 방대한 자료 덕분에 다양한 모델들이 개발되었습니다. 처음에는 바닥부터 새로 학습하는 방식이었습니다. 지금은 사전훈련된 모델을 내 데이터에 맞게 새로 파인튜닝하는 전이학습이 대세입니다.
그러나 여기에는 몇 가지 문제가 있습니다. 우선 라벨링하는데 시간과 노력이 너무 많이 들어갑니다. 또한 보통 1000개 정도의 클래스로 분류하도록 학습하기 때문에, 그 범위를 넘어가는 사진은 처리하기 어렵습니다. 그리고 ImageNet의 정제된 데이터셋에서는 잘 동작해도, 실제 현실의 다양한 사진에서는 정확도가 떨어집니다. CLIP은 이런 한계를 뛰어넘기 위해 새로운 접근을 하였습니다.
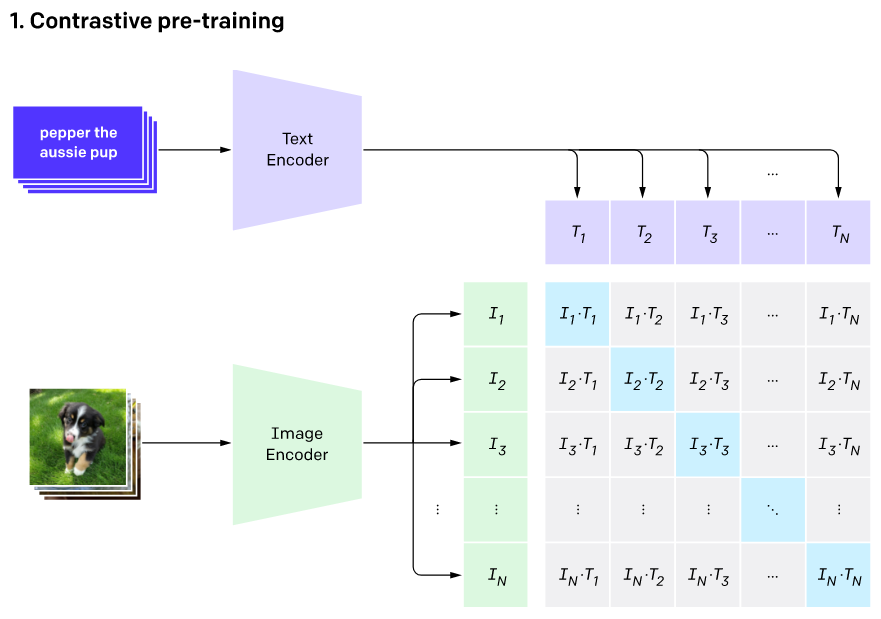
기존 모델은 사진을 입력받아 CNN으로 특징을 추출하고 미리 설정한 클래스의 개수만큼 인덱스로 분류합니다. 예를 들어, 강아지(0), 고양이(1), ..., 사자(98), 호랑이(99), 이런 식으로 사진의 해당 인덱스를 출력합니다. 반면에 CLIP은 이미지와 자연어를 멀티모달로 동시에 고려합니다.
인터넷에는 사진과 그 사진에 대한 설명 텍스트로 이루어진 데이터가 많습니다. 이런 데이터셋을 무려 4억개(ImageNet은 1500만개)를 수집했습니다. 그다음 사진과 텍스트를 각각의 인코더를 거쳐 벡터로 변환하고, 이 둘 사이의 유사도를 학습합니다. 인코더는 이미지의 경우 ResNet과 비전 트랜스포머, 텍스트는 트랜스포머 구조를 사용했습니다.
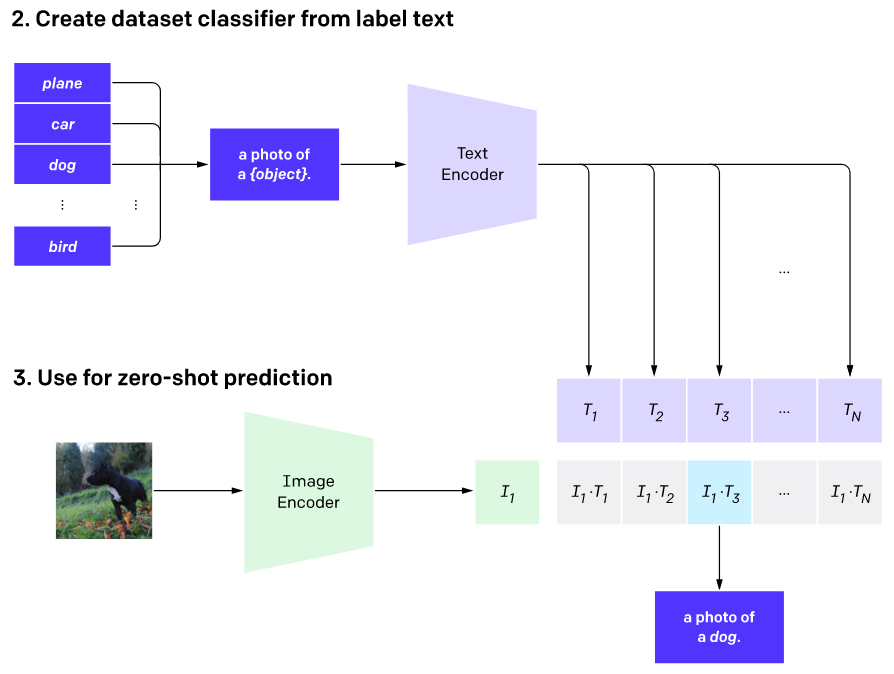
예측시에도 비슷한 방법을 씁니다. 만약 내가 100개의 동물을 분류하고 싶다면, '강아지 사진', 고양이 사진' 같이 그에 해당하는 클래스를 텍스트로 만듭니다. 그리고 입력 사진의 벡터와 100개 텍스트의 벡터들의 유사도를 구해 가장 높은 수치의 클래스를 선택합니다.
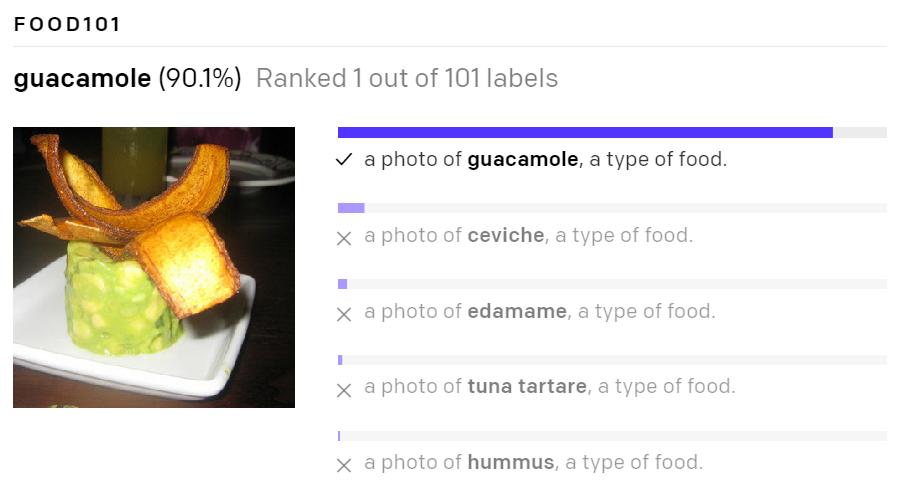
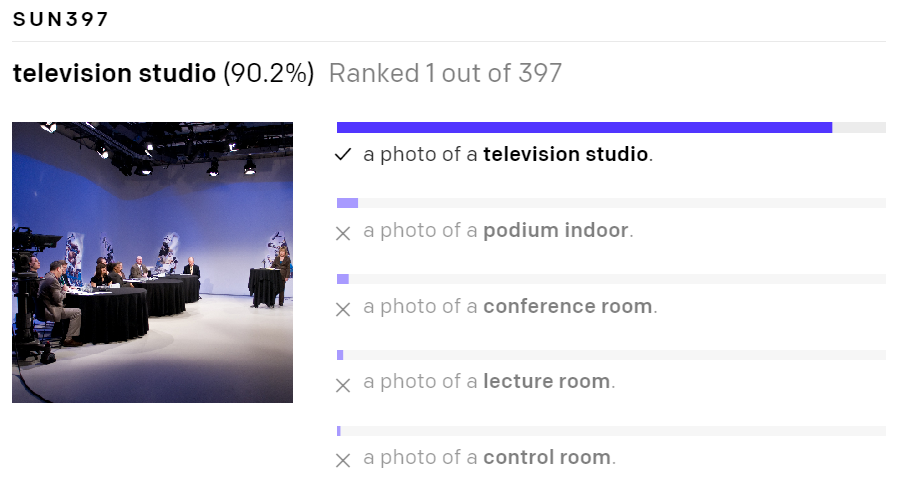
테스트 결과도 놀랍습니다. 기존 모델보다 높은 정확도를 자랑합니다. 특히 ImageNet의 형태를 벗어나는 애매한 사진들을 더 잘 판독합니다. 그만큼 견고하고 범용적인 모델이라 볼 수 있습니다.
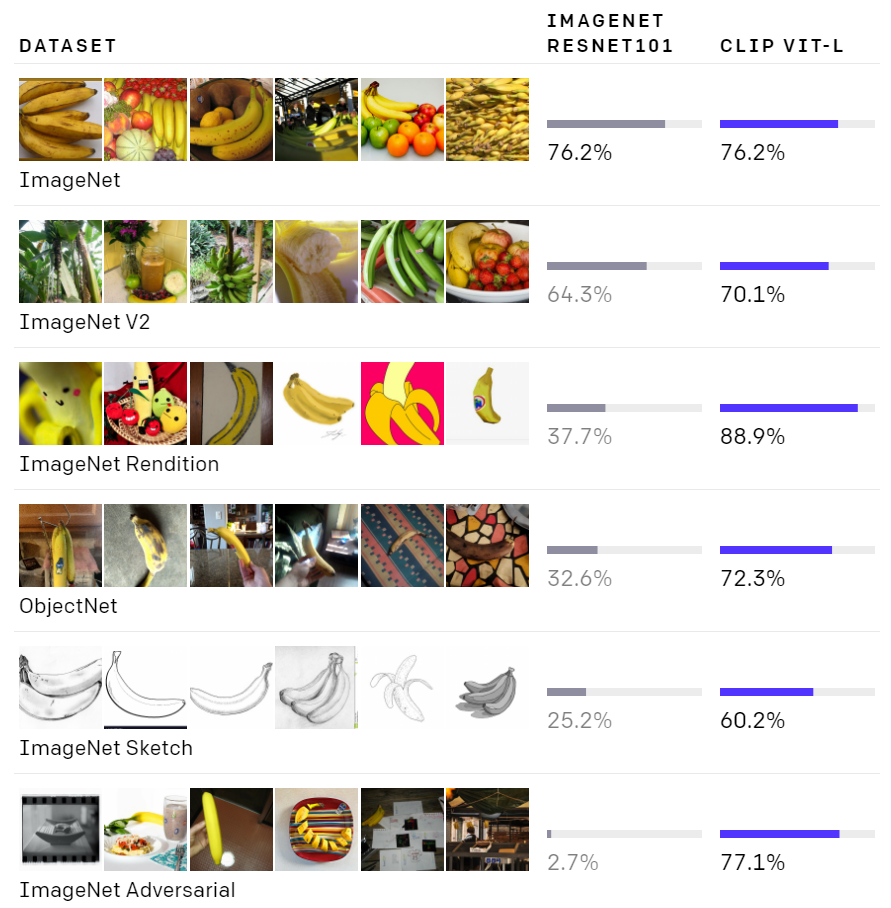
요즘 딥러닝이 점점 쉬워지는 방향으로 발전하고 있습니다. AutoML은 모델의 구조나 하이퍼파라미터를 자동으로 생성해줍니다. 클라우드 서비스에서 데이터만 올리고 바로 학습하고 서빙까지 하는 방법도 있습니다. 앞으로는 이것조차 사라지는 세상이 올지도 모릅니다. 그냥 CLIP 같은 초대형 모델이 제공하는 API를 사용하면 됩니다. 모델 구축도 학습도 필요가 없어집니다. 그냥 가져다 쓰기만 하면 됩니다. 물론 비용은 지불해야겠지만요. 이미 GPT-3가 자연어처리 분야에서 그런 단계를 밟고 있습니다. 이미지인식이나 다른 분야에서도 비슷한 방향으로 움직이지 않을까 예상해봅니다.