

- AI Dev - 인공지능 개발자 모임
- 정보공유
- 강화학습
소스코드 : 첨부파일
MDP(Markov Decision Process)의 개요
어떤 주어진 환경에서 최적의 행동을 결정하는 문제는 여러 분야에서 중요하게 고려되는 사항중의 하나이다. 예를 들어 아래 그림과 같이 현재 위치부터 목적지 까지 가장 최적의 길을 찾는 문제를 생각해보자.
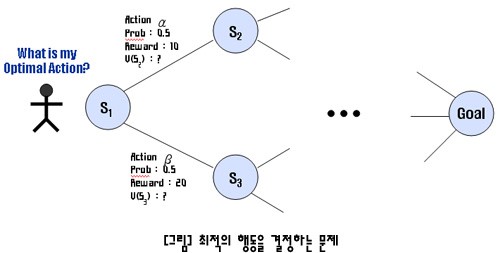
현재 위치에서 가능한 행동은 여러 방향 중 하나를 선택하는 것이다. 그런데 각 행동마다 결정할 수 있는 확률이 다르고(특정한 길을 더 좋아한다던지), 각 행동을 수행했을 때 주어지는 보상값이 다를 때(특정한 길이 더 빠르다면 높은 보상값을 얻는 것처럼), 현재 위치에서 최적의 행동을 결정할 수 있다면 목적지까지 가장 효율적으로 도착할 수 있을 것이다.
이러한 결정을 위해서 각 상태(위치)에서 확률과 보상값에 기반하여 각 행동을 수행했을 때의 행동값(V)을 계산할 수 있다면, 가장 높은 수치의 행동을 선택함으로써 최적의 행동을 결정할 수가 있다. 이러한 목적을 위해서 MDP 모델을 사용할 수 있다. MDP가 활용되는 분야는 로봇의 길찾기, 공장의 작업공정 조절 등 여러 복잡한 문제들에서 사용될 수 있다.
강화학습(Reinforcement Learning)으로의 확장
MDP 모델을 구현하기 위해서는 각 상태들을 정의할 수 있어야 하고, 각 행동마다 확률과 보상값이 주어져야 한다. 주어진 환경의 범위가 작을 경우에는 이러한 조건들을 얻을 수 있지만, 범위가 커질 경우 상태의 개수가 엄청나게 증가하고 확률이나 보상값을 결정하기 불가능할 수 있다.
이러한 경우에는 최적의 행동을 결정하기 위해 계산을 할 수가 없으므로 보통 강화학습이란 방법을 사용한다. 확률이나 보상값이 주어져있지 않아도 여러번 반복을 통한 학습으로 각 행동에 대한 행동값을 추정할 수 있다.
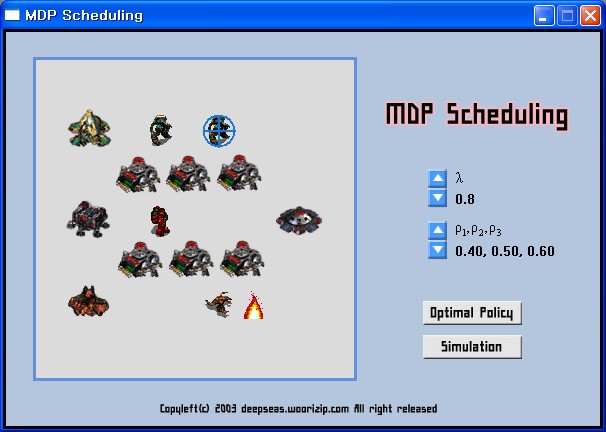
MDP기반의 스케줄링 구현
대학원 확률 동적 프로그래밍이란 과목의 프로젝트로 MDP를 사용하여 간단한 작업 스케줄링을 구현하여 보았다. 왼쪽의 건물에서 각각 다른 확률로 유닛들이 생성되고 각 유닛마다 다른 공격력을 가지고 있어 공격을 받았을 때의 피해정도가 다르다. 방어기지에서는 가장 피해가 적도록 유닛들을 선택하여 공격을 해야하는데, 각 확률(Rho)과 보상값(Lambda)을 변화시킬 때 최적이 행동을 결정하는 문제이다.
오른쪽의 확률과 보상값을 변화시킴에 따라 최적의 행동이 달라짐을 볼 수 있다. 예를 들어 보상값이 적은 유닛일 경우에는 그 유닛이 가까이 있어도 보상값이 큰 다른 유닛을 선택하는 행동을 결정하게 된다.
[참고자료]
- 논문 Algorithms for Sequential Decision Making, Michael Lederman Littman
참으로 흥미로운 프로그램입니다.
MDP를 공부하려는데 혹시 시중에 나온 좋은 서적이 있을까요?