

- AI Dev - 인공지능 개발자 모임
- 정보공유
- 챗봇 딥러닝
글 수 295
https://arxiv.org/pdf/1907.11692.pdf
며칠 전 페이스북에서 새로운 사전훈련 언어모델을 발표했습니다. 아직 그룹에 공유가 되지 않은 것 같아 간단하게 정리하였습니다. RoBERTa(Robustly Optimized BERT Pretraining Approach)는 BERT를 기반으로 하지만 다음과 같이 몇 가지 개선 사항이 있습니다.
1. NSP(Next Sentence Prediction) 제거
-> 기존 BERT는 특정 단어를 마스킹하여 맞히는 것과, 두 문장이 이어지는지 판단하는 두 가지 방법으로 학습을 합니다. 여기서 NSP를 빼고 마스킹만 사용하였습니다.
2. Dynamic Masking
-> 전처리에서 마스킹을 미리 하지 않고, 모델에 입력할 때 매번 마스킹을 변경합니다.
3. 학습 데이터 증가
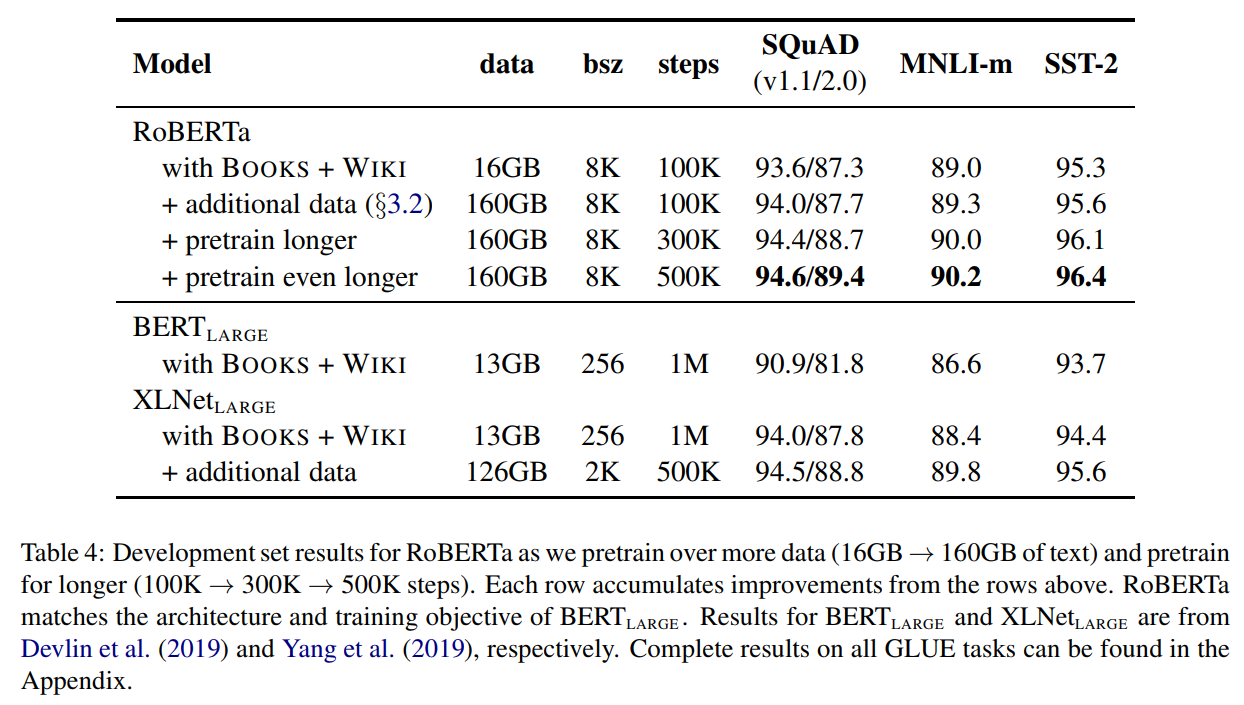
-> 16GB에서 160GB로 10배 커졌습니다.
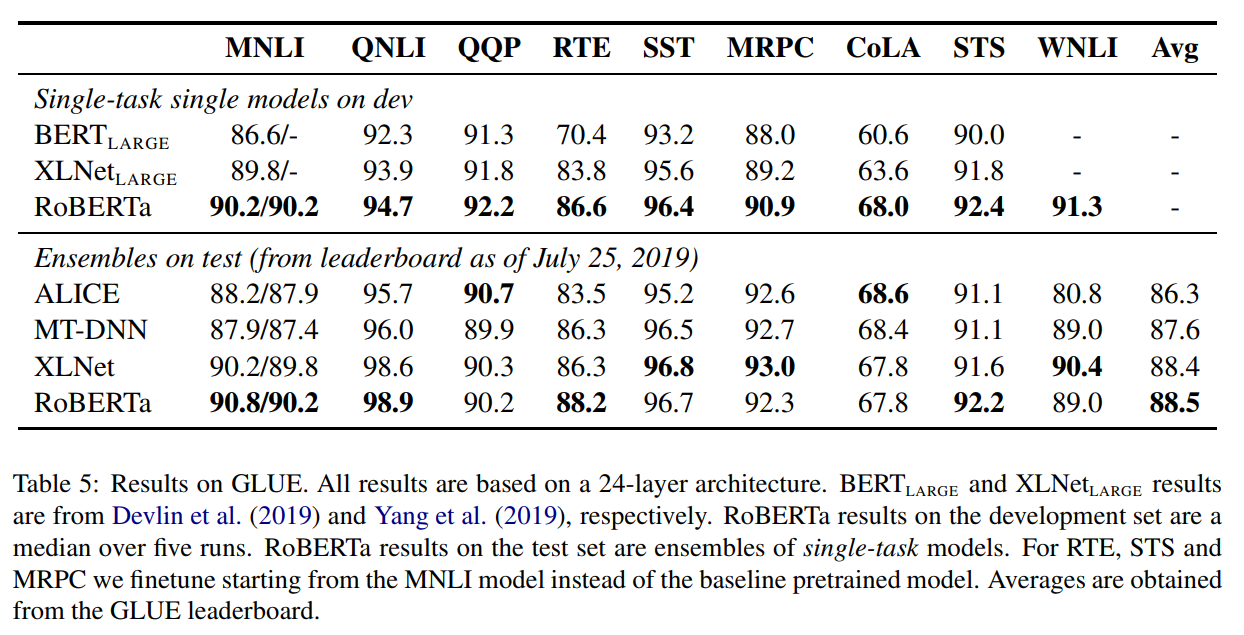
사진의 결과를 보면 RoBERTa가 BERT보다 월등한 성능을 보입니다. 또한 최근 공개된 XLNet을 근소한 차이로 앞서고 있습니다. 앞으로 사전훈련 방법을 개선한 다양한 모델이 나오지 않을까 생각됩니다.