

- AI Dev - 인공지능 개발자 모임
- 정보공유
- 강화학습
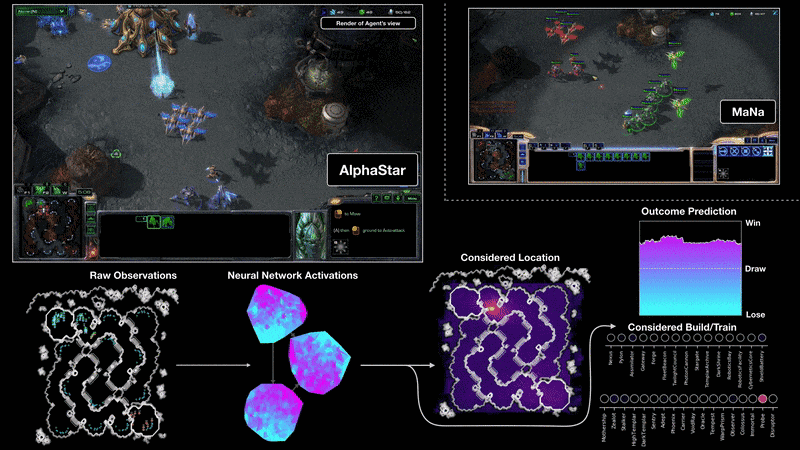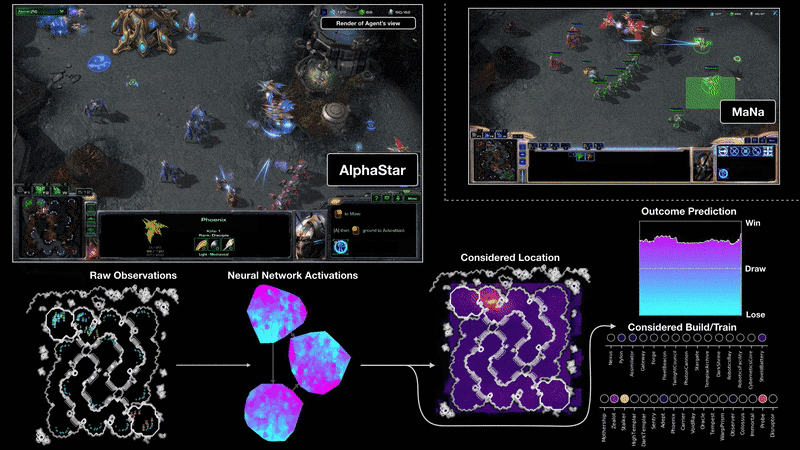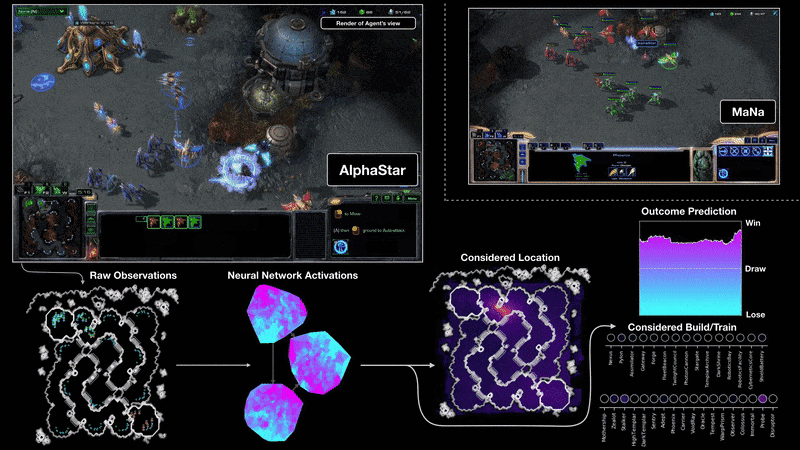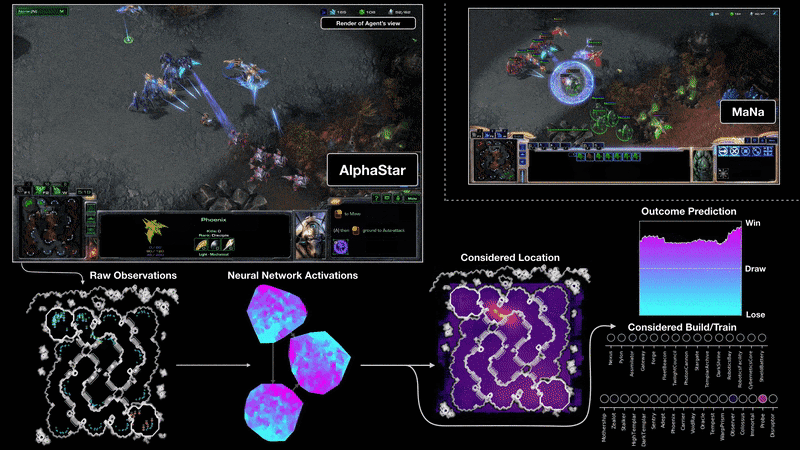
어제 드디어 딥마인드 알파스타가 프로게이머와 대결을 했습니다. 지금까지 전술차원의 간단한 데모만 보여줬는데 이번에는 전체 게임을 딥러닝으로 학습하여 플레이하였습니다.
몇 달전 중국 텐센트에서 공개한 인공지능은 큰 전략만 학습을 하고 해처리 빌드, 일꾼 생산 등 세부적인 컨트롤은 프로그래머가 하드코딩을 했습니다. 반면에 알파스타는 모든 부분을 학습으로만 구현했다고 합니다.
아직 자세한 논문이 발표되지 않아서 어떤 알고리즘을 썼는지 정확히 알 수 없습니다. 아래 블로그를 보면 Transformer가 기본 유닛이고 이를 LSTM으로 시간에 따른 상태를 처리하였습니다. Off-policy actor-critic reinforcement learning algorithm with experience replay, self-imitation learning, policy distillation 등을 기반으로 했다고 나와있는데 나중에 좀 더 살펴봐야겠습니다.
또 하나 특이한 점은 Population-based reinforcement learning을 사용했다는 것입니다. 하나의 개체로만 학습을 하지 않고 멀티 에이전트로 수많은 개체를 따로 만들어 서로 대전하며 실력을 향상시킵니다. 그리고 최고의 성적을 거둔 에이전트들을 앙상블하여 하나의 모델로 만든 것 같습니다.
바둑에 비해 스타크래프트는 훨씬 복잡하고 어려운 문제입니다. 2016년 알파고 이후 3년만에 허들 하나를 또 넘어섰습니다. 딥마인드의 다음 목표는 무엇일까요. 이번에는 게임을 벗어나 로봇같이 실제 생활에서 활용될 수 있는 분야면 좋겠습니다.
될 줄은 알았지만 이렇게 빨리되다니 놀랍네요;;